Semantic Librarian for any text (Alice in wonderland)
Alice.RmdA more general goal of Semantic Librarian is to create functions that can vectorize any kind of text corpus, and produce semantic vectors at the level of words, and any additional factor that is desired.
For example, previous Semantic Librarian’s have been deployed on scientific abstracts, and the functions were written to create word vectors, abstract vectors, and author vectors. A single abstract vector is formed by summing all of the word vectors contained in the abstract. A single author vector is formed by summing all of the abstract vector for that author.
The more general notion is that a series of texts (e.g., like abstracts) can be vectorized at a minimum to produce vectors for each word. Once the word vectors are obtained, additional vectors can be formed for any factor by addition. For example, if we consider author name to be a factor, then an author vector would be the sum of the word vectors used by that author.
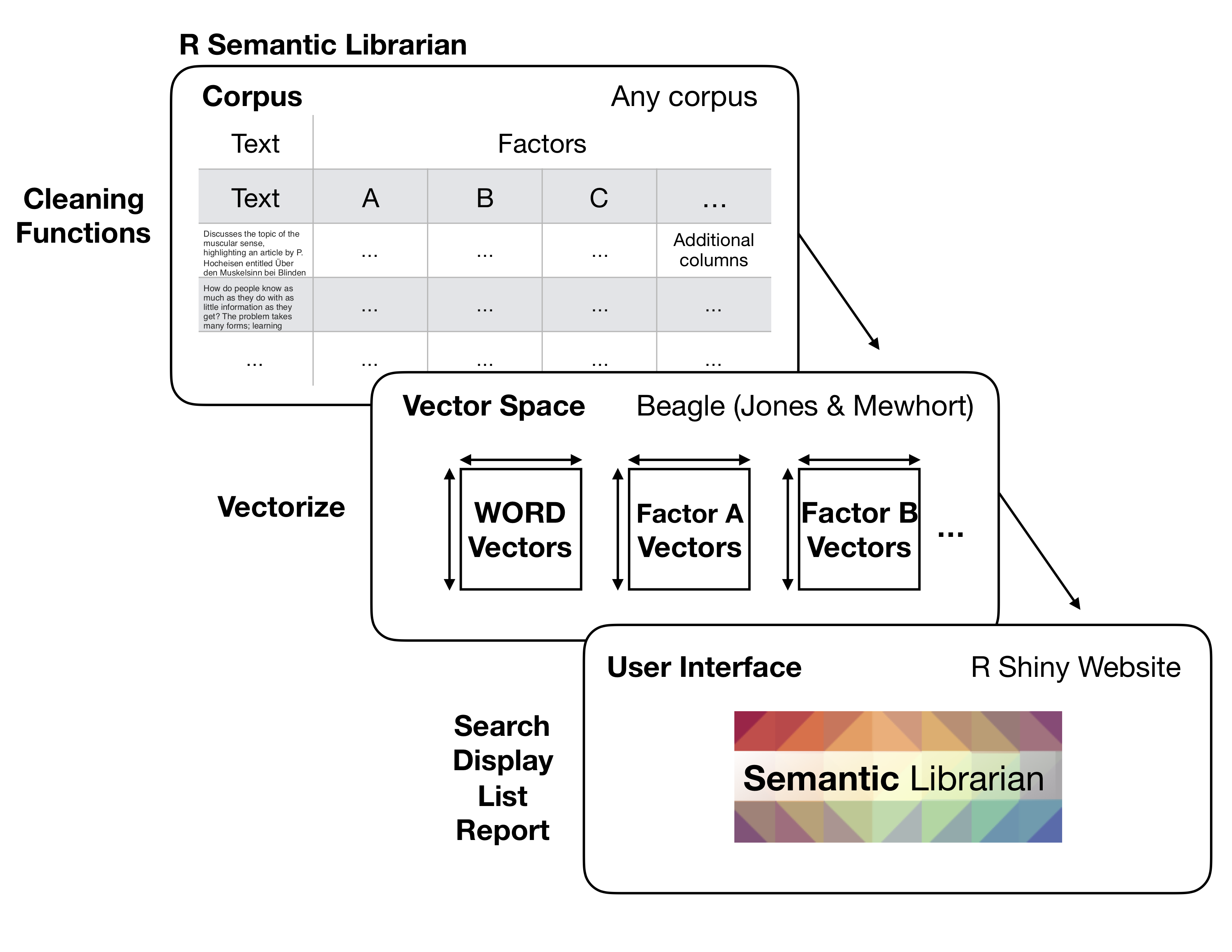
The figure below displays the very general notion, which is to have a dataframe including one column for each unit of text (e.g., a sentence or a paragraph), and additional factor columns that describe attributes of the text (e.g., the author, year, or any additional attribute).
Then, it would be wonderful to have some functions that would create the entire vector space (e.g., words, and factors), and then pump the vector space into a Shiny app for search and visualization.
Alice in wonderland
The Alice in wonderland is a minimal example for solving the above problem.
The source code is available in this repository:
https://github.com/CrumpLab/alice
The Shiny App that is produced can be viewed here:
https://semanticlibrarian.shinyapps.io/alice/
The remaining tutorial explains the major components of the alice example.
Alice overview
The text for Alice in Wonderland is in datafiles/alice.txt. The corpus_constructor.R file loads in the text and produces the vector space, which is stored in sl_data.RData as a list. The shiny app app.R loads the vector space and allows search and display of similarity between items in the same or different vector space.
Current limitations
Although the intention behind this example is to show how any text corpus could be vectorized and loaded into a Shiny app, there are some limitations. For example, the text for alice and wonderland was itemized at the sentence level. As a result, each row in the dataframe is a sentence, with periods removed. Some of the functions for rendering the vectors were written to handle this particular case. As a result, the example will not work as intended if the rows of text contain larger units, such as paragraphs with periods. These kinds of issues will be addressed in future versions.
corpus_constructor
Below is a walk through of the code to create the Alice and Wonderland vector space. Step 1 is to load libraries.
The text source is loaded and converted into sentences. The breakdown function from the LSAfun package is used to clean the text a bit, and convert to lowercase. A bit of further cleaning is done by rm_endmark from the qdapRegex. In general, text sources are fickle, and cleaning them properly can take time and effort. The goal is to produce lower case words, with special characters removed, and periods as sentence markers.
# Load text
alice <- scan(file="datafiles/Alice.txt", what=character())
alice <- paste(alice, sep=" ", collapse=" ")
alice <- unlist(strsplit(alice,split="[.]"))
alice <- LSAfun::breakdown(alice)
alice <- qdapRegex::rm_endmark(alice)A dataframe is created with a column for the sentences, and three additional arbitrary factor columns.
# Make tidystyle dataframe (text, factor columns, index added for convenience)
text_df <- data.table(sentences = alice,
index=1:length(alice),
factor1 = sample(letters,replace=TRUE,length(alice)),
factor2 = sample(letters,replace=TRUE,length(alice)),
factor3 = sample(letters,replace=TRUE,length(alice))
)
text_df <- data.frame(text_df)Below three functions are defined that are customized from this example. These functions are not in RsemanticLibrarian, but they are modified from existing functions in RsemanticLibrarian.
sl_clean_vector2 does additional cleaning of the text.
factor_vectors creates vectors for each each level of each factor. The resultant vectors are the sum of the words that occured for each factor level.
sl_semantic_general is a wrapper function with some customization and some calls to RsemanticLibrarian. It runs the entire process of creating all semantic vectors.
# Define a few functions
# deals with sentences that have no periods
sl_clean_vector2 <- function(words){
return(lapply(words,sl_clean))
}
# create vectors for each factor
factor_vectors <- function(at_list,
articles = article_df,
fct = the_factor,
a_vectors = article_vectors) {
author_vectors <- matrix(0, ncol = dim(a_vectors)[2], nrow = length(at_list))
for(i in 1:length(at_list)){
#auth_ids <- which(articles$authorlist %in% at_list[i])
auth_ids <- which(stringr::str_detect(articles[,fct],at_list[i]))
if(length(auth_ids) > 1) {
author_vectors[i,] <- colSums(a_vectors[auth_ids,])
} else {
author_vectors[i,] <- a_vectors[auth_ids,]
}
}
return(author_vectors)
}
# generate all vectors, return sl_data list
sl_semantic_general <- function(abstract_df=text_df,
text_column = "sentences",
factor_columns,
riv_param = c(100,6)){
vector_corpus <- list()
# create corpus dictionary
vector_corpus[['word_terms']] <- sl_corpus_dictionary(
unlist(abstract_df[,text_column], use.names=FALSE)
)
message("Semantic Librarian: corpus dictionary created...")
# convert to sentences, clean
clean_sentences <- sl_clean_vector2(
unlist(abstract_df[,text_column], use.names=FALSE)
)
message("Semantic Librarian: Cleaned sentences...")
# word ids for sentences
sentence_ids <- sl_word_ids_sentences(clean_sentences,vector_corpus[['word_terms']])
message("Semantic Librarian: Created word IDs for sentences...")
# Create word vectors
message("Semantic Librarian: Creating BEAGLE word vectors...")
vector_corpus[['word_vectors']] <- sl_beagle_vectors(s_ids = sentence_ids,
dictionary = vector_corpus[['word_terms']],
riv = riv_param,
verbose = 500)
# get text vectors
the_abstracts <- list()
the_abstracts[['new']] <- abstract_df[,text_column]
clean_abstracts <- lapply(the_abstracts$new,
sl_clean)
message("Semantic Librarian: cleaning text...")
abstract_word_ids <- sl_word_ids_sentences(clean_abstracts,vector_corpus[['word_terms']])
message("Semantic Librarian: Making text-word IDs...")
message("Semantic Librarian: Making text vectors...")
vector_corpus[[paste(text_column,"vectors",sep="_",collapse='')]] <- sl_article_vectors(abstract_word_ids, w_matrix = vector_corpus[['word_vectors']])
vector_corpus[[paste(text_column,"terms",sep="_",collapse='')]] <- abstract_df[,text_column]
#get factor vectors
message("Semantic Librarian: Making factor vectors...")
for(i in factor_columns){
vector_corpus[[paste(i,"terms",sep="_",collapse='')]] <- unique(abstract_df[,i])
vector_corpus[[paste(i,"vectors",sep="_",collapse='')]] <- factor_vectors(at_list = vector_corpus[[paste(i,"terms",sep="_",collapse='')]],
articles = abstract_df,
fct = i,
a_vectors = vector_corpus[[paste(text_column,"vectors",sep="_",collapse='')]])
}
message("Semantic Librarian: Corpus Complete")
return(vector_corpus)
}Now we run the function to create the vector space and save the vector data.
Shiny app.r
The contents of the data file sl_data.RData are then loaded into this Shiny app. This tutorial is limited in scope and does not detail each aspect of the Shiny code.
# minimal example for creating a semantic librarian
# corpus: Alice and Wonderland
# author: Matt Crump
# load data #####
load(file = "sl_data.RData", envir=.GlobalEnv)
# load libraries #####
library(shiny)
library(shinyjs)
library(lsa)
library(LSAfun)
library(ggplot2)
library(DT)
library(dplyr)
library(Rcpp)
library(ggrepel)
library(rvest)
library(stringr)
## load functions ####
source("functions/semanticL.R")
`%then%` <- shiny:::`%OR%`
# define UI ####
ui <- fluidPage(
# Application title
titlePanel("Search Alice"),
# Sidebar to choose vector spaces
sidebarLayout(
sidebarPanel(
selectInput("search_vectors", label = "Search Vector Space",
choices = NULL),
selectInput("target_vectors", label = "Target Vector Space",
choices = NULL),
selectInput("search_terms", label = "Search terms",
choices = NULL),
sliderInput("num_items", label = "number of items", min = 5,
max = 30, value = 10, step=1),
sliderInput("num_clusters", label = "number of clusters", min = 1,
max = 4, value = 2, step=1)
),
# Main panel for plot and table
mainPanel(
plotOutput("sl_plot"),
DT::dataTableOutput("sl_table")
)
)
)
# define server ####
server <- function(input, output, session) {
## Initialize Reactive variables ####
values <- reactiveValues()
# Update and populate vector selection options ####
sl_data_names <- names(sl_data)
vector_spaces <- sl_data_names[str_detect(names(sl_data),"_vector")]
vector_terms <- sl_data_names[str_detect(names(sl_data),"_terms")]
updateSelectizeInput(session,'search_vectors', label = "Search Vector Space",
choices = vector_spaces)
updateSelectizeInput(session,'target_vectors', label = "Target Vector Space",
choices = vector_spaces)
observeEvent(input$search_vectors,{
splitter <- unlist(strsplit(input$search_vectors,split="_"))
values$term_choice <- sl_data_names[str_detect(names(sl_data),
paste(splitter[1],"_terms",sep="",collapse=''))]
print(values$term_choice)
updateSelectizeInput(session,'search_terms', label = "Search Terms",
choices = sl_data[values$term_choice], selected=sl_data[values$term_choice][1])
})
observeEvent(input$target_vectors,{
splitter <- unlist(strsplit(input$target_vectors,split="_"))
values$target_terms <- sl_data_names[str_detect(names(sl_data),
paste(splitter[1],"_terms",sep="",collapse=''))]
})
# MAIN OBSERVE FUNCTION
observe({
validate(
need(input$search_terms != "","none")
)
# get similarities
sim_df <- get_similarities(input$search_terms,
sl_data[[values$term_choice]],
sl_data[[input$search_vectors]],
sl_data[[input$target_vectors]],
sl_data[[values$target_terms]])
req(is.null(dim(sim_df)) == FALSE)
# get MDS solution
mds_SS <- get_mds_fits(num_items = input$num_items,
num_clusters = input$num_clusters,
input_df = sim_df,
target_vectors = sl_data[[input$target_vectors]],
target_terms = sl_data[[values$target_terms]])
# output table
output$sl_table <- DT::renderDT({
return(sim_df[1:100,])
}, options = list(pageLength=10), rownames=FALSE,
escape=FALSE, selection = 'none')
# output plot
output$sl_plot <- renderPlot({
validate(
need(input$search_terms != "","none"),
need(is.null(dim(sim_df)) == FALSE,"none")
)
ggplot(mds_SS, aes(x= X, y= Y,
color=as.factor(cluster),
# text=terms,
label=terms))+
geom_label_repel(size=4, color= "black",
label.size=0,
force=5)+
geom_point(size = 3, alpha=.75)+
theme_void()+
theme(legend.position = "none")
})
})
}
# Run the application
shinyApp(ui = ui, server = server)