
Chapter 1 Lab 1: Graphing Data
The commonality between science and art is in trying to see profoundly - to develop strategies of seeing and showing. —Edward Tufte
As we have found out from the textbook and lecture, when we measure things, we get lots of numbers. Too many. Sometimes so many your head explodes just thinking about them. One of the most helpful things you can do to begin to make sense of these numbers, is to look at them in graphical form. Unfortunately, for sight-impaired individuals, graphical summary of data is much more well-developed than other forms of summarizing data for our human senses. Some researchers are developing auditory versions of visual graphs, a process called sonification, but we aren’t prepared to demonstrate that here. Instead, we will make charts, and plots, and things to look at, rather than the numbers themselves, mainly because these are tools that are easiest to get our hands on, they are the most developed, and they work really well for visual summary. If time permits, at some point I would like to come back here and do the same things with sonification. I think that would be really, really cool!
1.1 General Goals
Our general goals for this first lab are to get your feet wet, so to speak. We’ll do these things:
- Load in some data to a statistical software program
- Talk a little bit about how the data is structured
- Make graphs of the data so we can look at it and make sense of it.
1.1.1 Important info
Data for NYC film permits was obtained from the NYC open data website. The .csv file can be found here: Film_Permits.csv
Gapminder data from the gapminder project (copied from the R gapminder library) can be downloaded in .csv format here: gapminder.csv
1.2 R
1.2.1 Download the lab templates
You will be completing each lab by writing your code and notes in an R Markdown document.
- Download the RMarkdownsLab.zip to your computer.
- Unzip the file, this will produce a new folder with three important parts
- data folder (contains data files for all labs)
- LabTemplates folder (contains blank templates for completing all the labs)
- RMarkdownsLab.Rproj A file with a little blue cube with an R in it.
- Double-click the RMarkdownsLab.Rproj file, this will automatically open R-studio (if you are at home, you must install R and R-studio first, or you can use R-studio Cloud through your web-browser)
- Copy the template .Rmd file for lab 1 from the LabTemplates folder into the main folder, then open it, and use it to begin adding your code and notes for lab 1.
- Watch this screencast to help you get started.
Your lab instructor will show you how to open R-studio on the lab computer. Just find it and double-click. Now you have R-studio. Your lab instructor will also walk you through the steps to get started completing the first lab. We also wrote down the steps here.
There are numerous resources for learning about R, we put some of them on the course website, under the resouces page. You will find these resources helpful as you learn. We also have a kind of general introduction to R and Rstudio here. This shows you how to download R and R-studio at home (it’s free). Throughout the labs you will be writing things called R Markdown documents. You will learn how to do this throughout the labs, but it can also be worthwhile reading other tutorials, such as the one provided by R Markdown.
When we made this course, we assumed that most students would be unfamiliar with R and R-studio, and might even be frightened of it, because it is a computer programming language (OOOOHHH NOOOOOOO, I NEED TO DROP THIS COURSE NOW)…Don’t worry. It’s going to be way easier than you think. Let’s compare to other statistics courses where you would learn something like SPSS. That is also a limited programming language, but you would mostly learn how to point with a mouse, and click with button. I bet you already know how to do that. I bet you also already know how to copy and paste text, and press enter. That’s mostly what we’ll be doing to learn R. We will be doing statistics by typing commands, rather than by clicking buttons. However, lucky for you, all of the commands are already written for you. You just have to copy/paste them.
We know that this will seem challenging at first. But, we think that with lots of working examples, you will get the hang of it, and by the end of the course you will be able to do things you might never have dreamed you can do. It’s really a fantastic skill to learn, even if you aren’t planning on going on to do research in Psychology (in which case, this kind of thing is necessary skill to learn). With that, let’s begin.
1.2.2 Get some data
In order to graph data, we need to have some data first…Actually, with R, that’s not quite true. Run this bit of code and see what happens:
hist(rnorm(100, mean=50, sd=25))
You just made R sample 100 numbers, and then plot the results in a histogram. Pretty neat. We’ll be doing some of this later in the course, where get R to make fake data for us, and then we learn to think about how data behaves under different kinds of assumptions.
For now, let’s do something that might be a little bit more interesting…what movies are going to be filming in NYC? It turns out that NYC makes a lot of data about a lot things open and free for anyone to download and look at. This is the NYC Open Data website: https://opendata.cityofnewyork.us. I searched through the data, and found a data file that lists the locations of film permits for shooting movies all throughout the Burroughs. There are multiple ways to load this data into R.
- If you have downloaded the RMarkdownsLab.zip file, then you already have the data file in the data folder. Assuming you are working in your main directory (your .rmd file is saved in the main folder that contains both the data and template folders), then use the following commands to load the data.
library(data.table)
nyc_films <-fread("data/Film_Permits.csv")- If the above method doesn’t work, you can try loading the data from the course website using:
library(data.table)
nyc_films <- fread("https://raw.githubusercontent.com/CrumpLab/statisticsLab/master/data/Film_Permits.csv")If you are having issues getting the data loaded, then talk to your lab instructor
1.2.3 Look at the data
You will be downloading and analyzing all kinds of data files this semester. We will follow the very same steps every time. The steps are to load the data, then look at it. You want to see what you’ve got.
In R-studio, you will now see a variable called nyc_films in the top right-hand corner of the screen, in the environment tab. If you click this thing, it will show you the contents of the data in a new window. The data is stored in something we call a data frame. It’s R lingo, for the thing that contains the data. Notice is a square, with rows going across, and columns going up and down. It looks kind of like an excel spreadsheet if you are familiar with Excel.
It’s useful to know you can look at the data frame this way if you need to. But, this data frame is really big, it has 50,728 rows of data. That’s a lot too much to look at.
1.2.3.1 summarytools
The summarytools packages give a quick way to summarize all of the data in a data frame. Here’s how. When you run this code you will see the summary in the viewer on the bottom right hand side. There’s a little browser button (arrow on top of little window) that you can click to expand and see the whole thing in a browser.
library(summarytools)
view(dfSummary(nyc_films))That is super helpful, but it’s still a lot to look at. Because there is so much data here, it’s pretty much mind-boggling to start thinking about what to do with it.
1.2.4 Make Plots to answer questions
Let’s walk through a couple questions we might have about this data. We can see that there were 50,728 film permits made. We can also see that there are different columns telling us information about each of the film permits. For example, the Borough column lists the Borough for each request, whether it was made for: Manhattan, Brooklyn, Bronx, Queen’s, or Staten Island. Now we can ask our first question, and learn how to do some plotting in R.
1.2.4.1 Where are the most film permits being requested?
Do you have any guesses? Is it Manhattan, or Brooklyn, of the Bronx? Or Queen’s or Staten Island? We can find out by plotting the data using a bar plot. We just need to count how many film permits are made in each borough, and then make different bars represent the the counts.
First, we do the counting in R. Run the following code.
library(dplyr)
counts <- nyc_films %>%
group_by(Borough) %>%
summarize(count_of_permits = length(Borough))The above grouped the data by each of the five Borough’s, and then counted the number of times each Borough occurred (using the length function). The result is a new variable called count. I chose to name this variable count. You can see that it is now displayed in the top-right hand corned in the environment tab. If you gave count a different name, like muppets, then it would be named what you called it.
If you click on the counts variable, you will see the five boroughs listed, along with the counts for how many film permits were requested in each Borough. These are the numbers that we want to plot in a graph.
We do the plot using a fantastic package called ggplot2. It is very powerful once you get the hand of it, and when you do, you will be able to make all sorts of interesting graphs. Here’s the code to make the plot
library(ggplot2)
ggplot(counts, aes(x = Borough, y = count_of_permits )) +
geom_bar(stat="identity")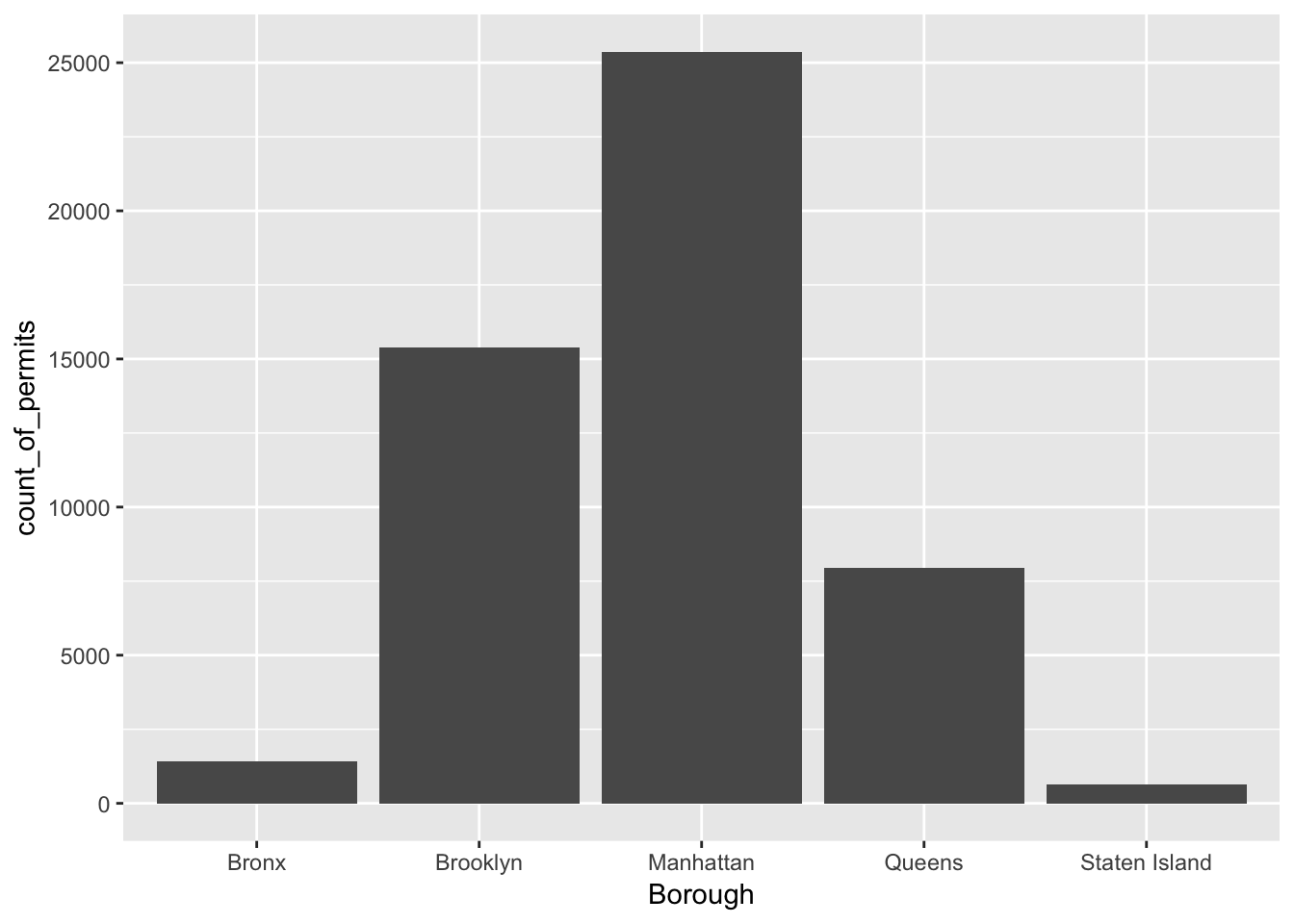
There it is, we’re done here! We can easily look at this graph, and answer our question. Most of the film permits were requested in Manhattan, followed by Brooklyn, then Queen’s, the Bronx, and finally Staten Island.
1.2.4.2 What kind of “films” are being made, what is the category?
We think you might be skeptical of what you are doing here, copying and pasting things. Soon you’ll see just how fast you can do things by copying and pasting, and make a few little changes. Let’s quickly ask another question about what kinds of films are being made. The column Category, gives us some information about that. Let’s just copy paste the code we already made, and see what kinds of categories the films fall into. See if you can tell what I changed in the code to make this work, I’ll do it all at once:
counts <- nyc_films %>%
group_by(Category) %>%
summarize(count_of_permits = length(Category))
ggplot(counts, aes(x = Category, y = count_of_permits )) +
geom_bar(stat="identity")+
theme(axis.text.x = element_text(angle = 90, hjust = 1))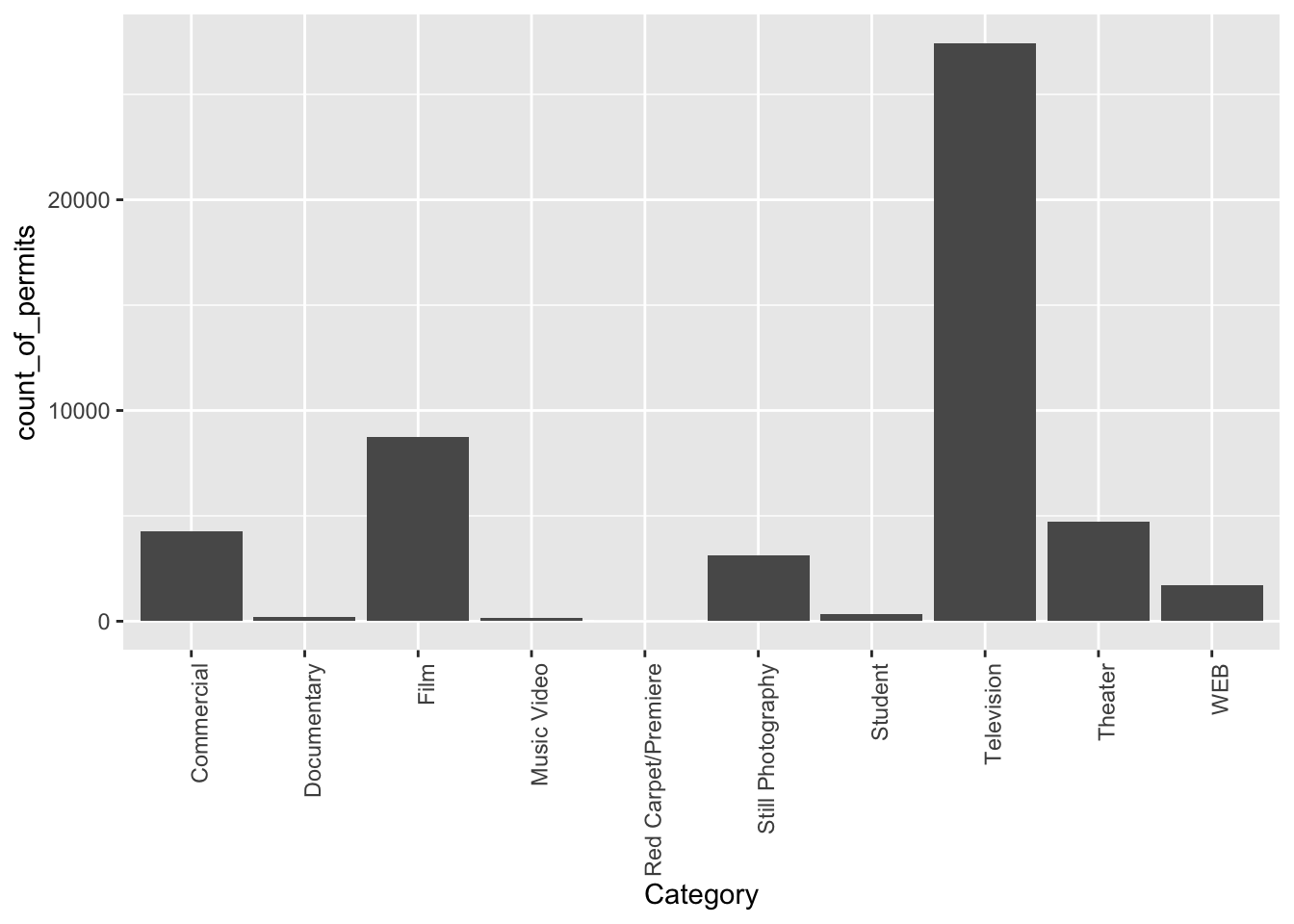
OK, so this figure might look a bit weird because the labels on the bottom are running into each other. We’ll fix that in a bit. First, let’s notice the changes.
I changed
BoroughtoCategory. That was the main thingI left out a bunch of things from before. None of the
library()commands are used again, and I didn’t re-run the very early code to get the data. R already has those things in it’s memory, so we don’t need to do that first. If you ever clear the memory of R, then you will need to reload those things. First-things come first.
Fine, so how do we fix the graph? Good question. To be honest, I don’t know right now. I totally forgot how. But, I know ggplot2 can do this, and I’m going to Google it, right now. Then I’m going to find the answer, and use it here. The googling of your questions is a fine way to learn. It’s what everybody does these days….[goes to Google…].
Found it, actually found a lot of ways to do this. The trick is to add the last line. I just copy-pasted it from the solution I found on stack overflow (you will become friend’s with stack overflow, there are many solutions there to all of your questions)
counts <- nyc_films %>%
group_by(Category) %>%
summarize(count_of_permits = length(Category))
ggplot(counts, aes(x = Category, y = count_of_permits )) +
geom_bar(stat="identity")+
theme(axis.text.x = element_text(angle = 90, hjust = 1))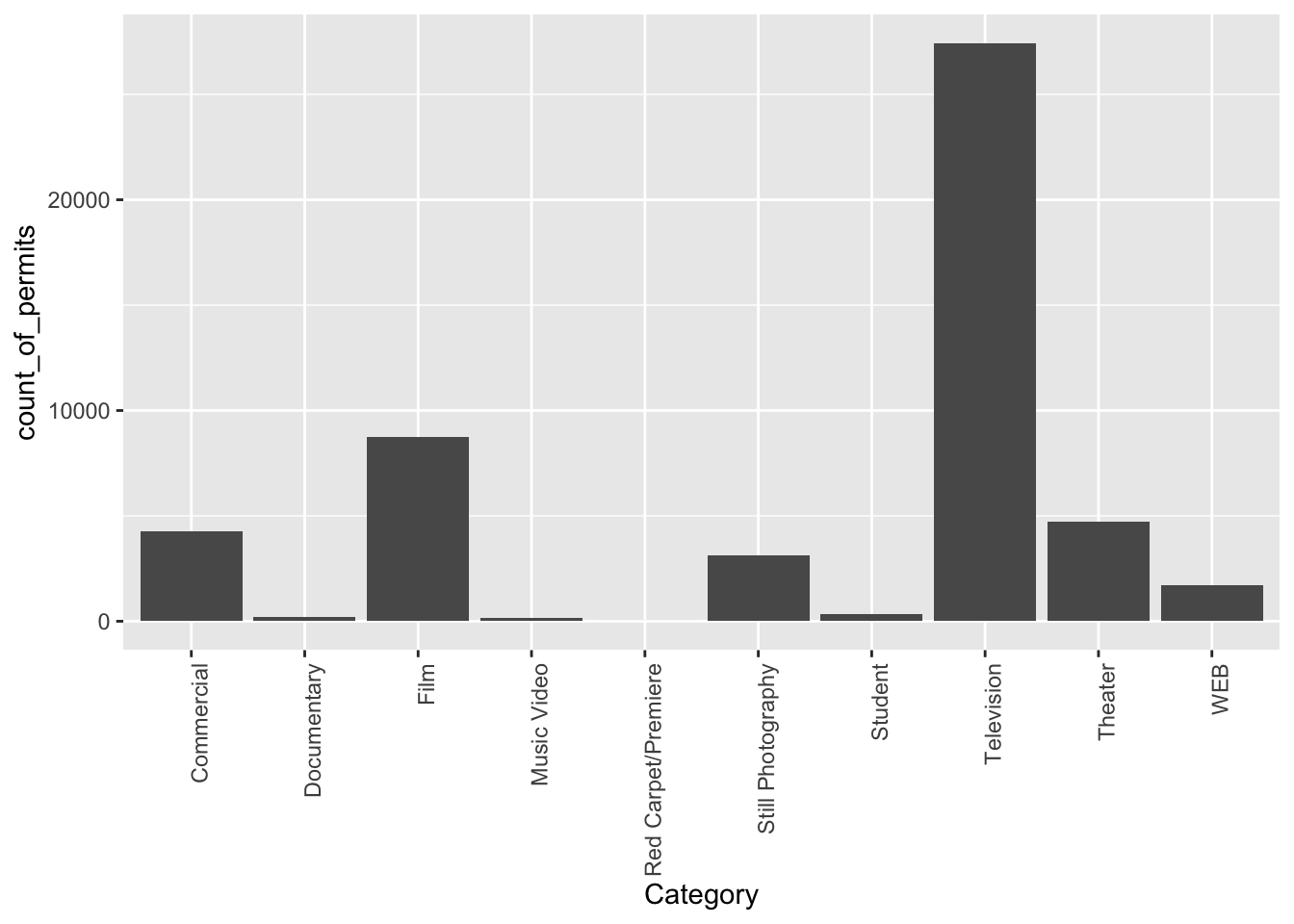
1.2.5 ggplot2 basics
Before we go further, I want to point out some basic properties of ggplot2, just to give you a sense of how it is working. This will make more sense in a few weeks, so come back here to remind yourself. We’ll do just a bit a basics, and then move on to making more graphs, by copying and pasting.
The ggplot function uses layers. Layers you say? What are these layers? Well, it draws things from the bottom up. It lays down one layer of graphics, then you can keep adding on top, drawing more things. So the idea is something like: Layer 1 + Layer 2 + Layer 3, and so on. If you want Layer 3 to be Layer 2, then you just switch them in the code.
Here is a way of thinking about ggplot code
ggplot(name_of_data, aes(x = name_of_x_variable, y = name_of_y_variable)) +
geom_layer()+
geom_layer()+
geom_layer()
What I want you to focus on in the above description is the \(+\) signs. What we are doing with the plus signs is adding layers to plot. The layers get added in the order that they are written. If you look back to our previous code, you will see we add a geom_bar layer, then we added another layer to change the rotation of the words on the x-axis. This is how it works.
BUT WAIT? How am I supposed to know what to add? This is nuts! We know. You’re not supposed to know just yet, how could you? We’ll give you lots of examples where you can copy and paste, and they will work. That’s how you’ll learn. If you really want to read the help manual you can do that too. It’s on the ggplot2 website. This will become useful after you already know what you are doing, before that, it will probably just seem very confusing. However, it is pretty neat to look and see all of the different things you can do, it’s very powerful.
For now, let’s the get the hang of adding things to the graph that let us change some stuff we might want to change. For example, how do you add a title? Or change the labels on the axes? Or add different colors, or change the font-size, or change the background? You can change all of these things by adding different lines to the existing code.
1.2.5.1 ylab() changes y label
The last graph had count_of_permits as the label on the y-axis. That doesn’t look right. ggplot2 automatically took the label from the column, and made it be the name on the y-axis. We can change that by adding ylab("what we want"). We do this by adding a \(+\) to the last line, then adding ylab()
ggplot(counts, aes(x = Category, y = count_of_permits )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits")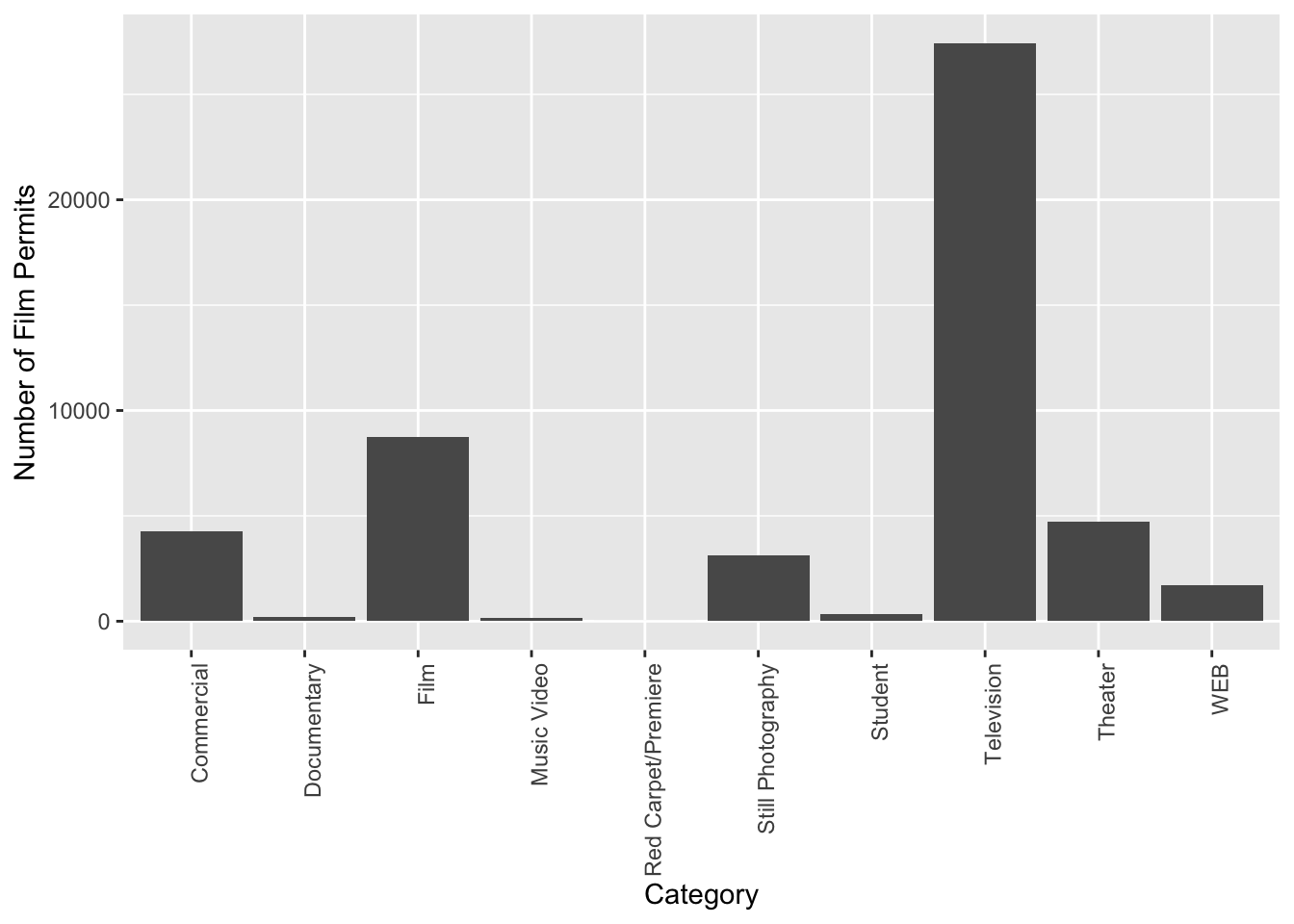
1.2.5.2 xlab() changes x label
Let’s slightly modify the x label too:
ggplot(counts, aes(x = Category, y = count_of_permits )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film")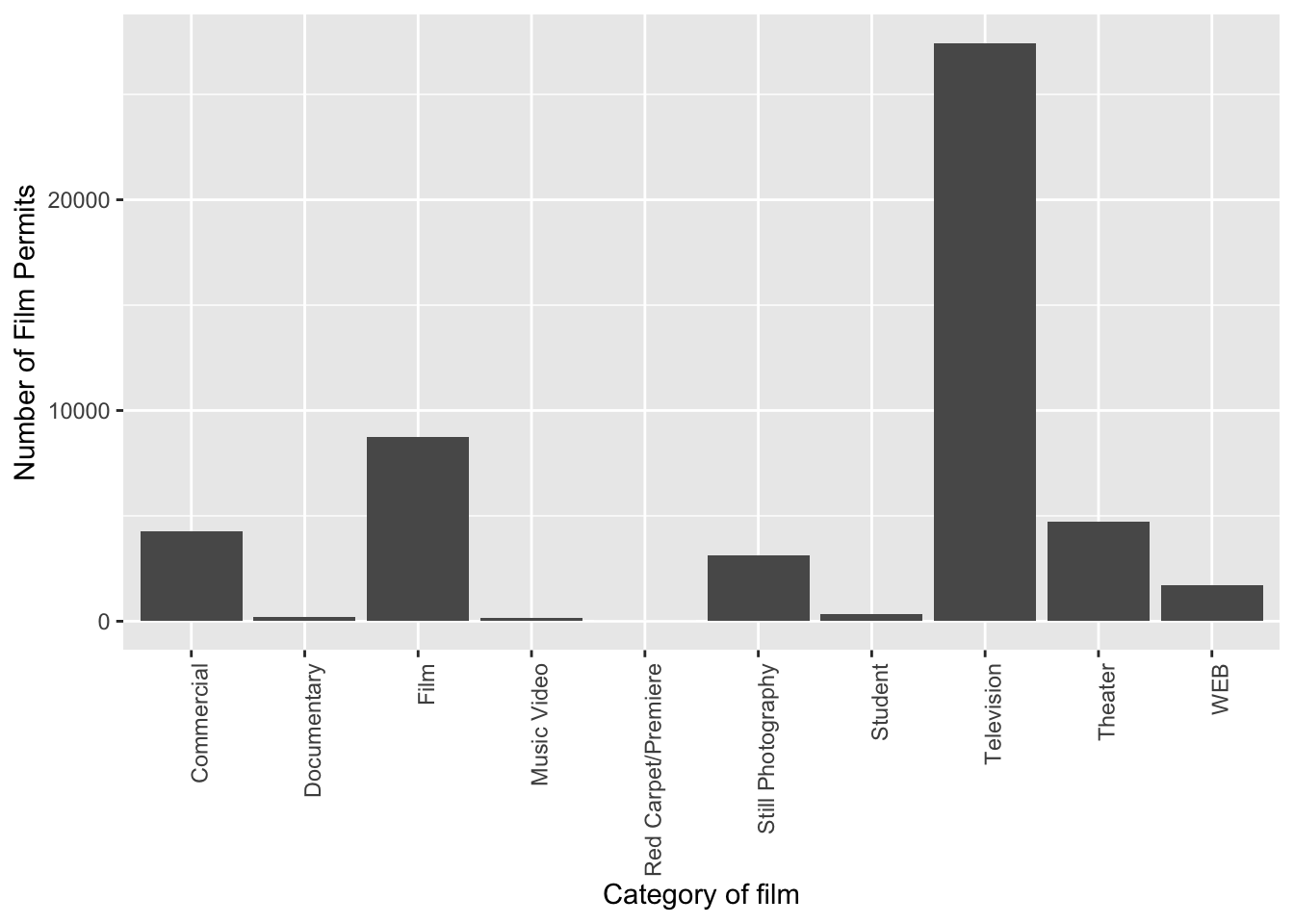
1.2.5.3 ggtitle() adds title
Let’s give our graph a title
ggplot(counts, aes(x = Category, y = count_of_permits )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category")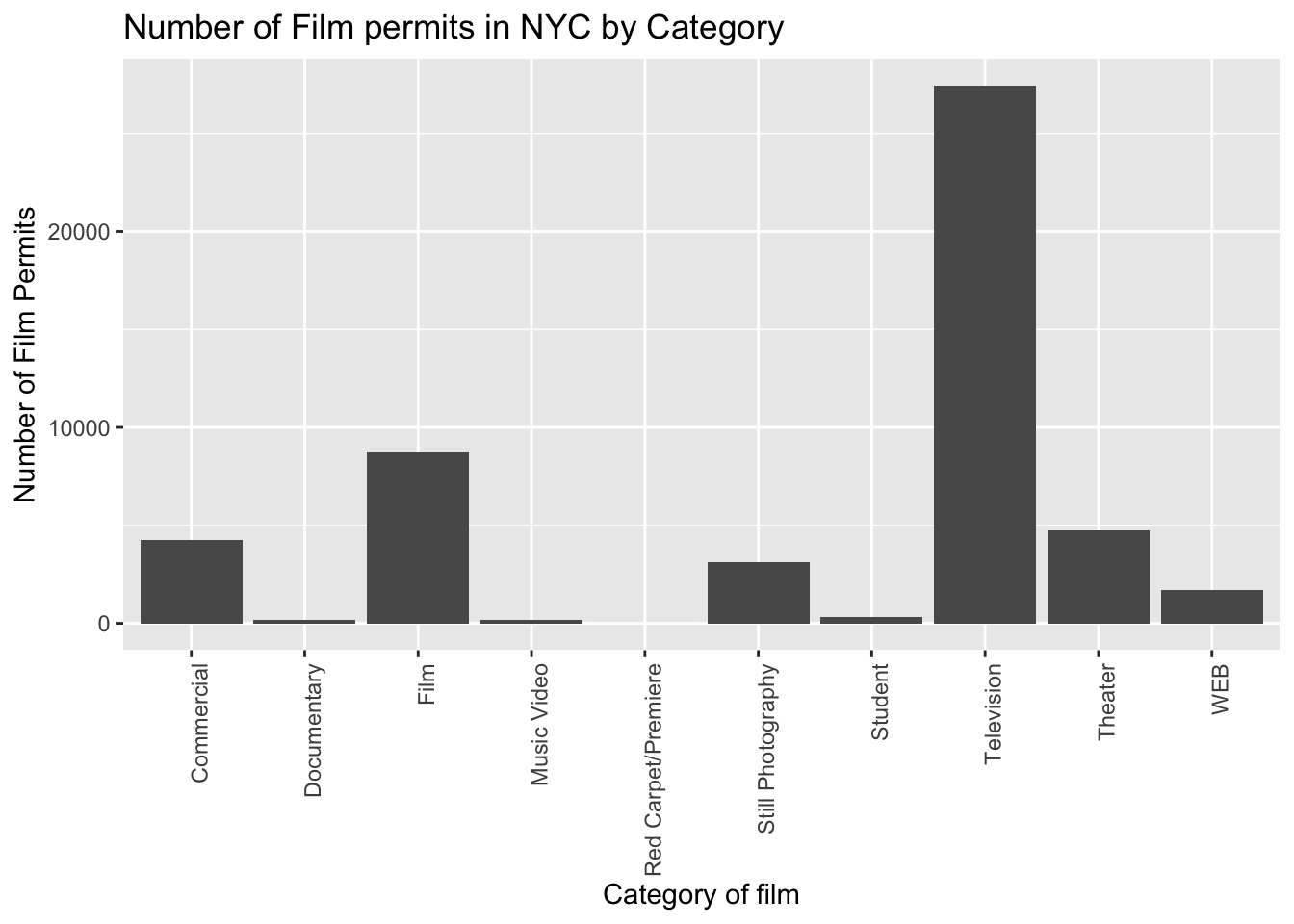
1.2.5.4 color adds color
Let’s make the bars different colors. To do this, we add new code to the inside of the aes() part:
ggplot(counts, aes(x = Category, y = count_of_permits, color=Category )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category")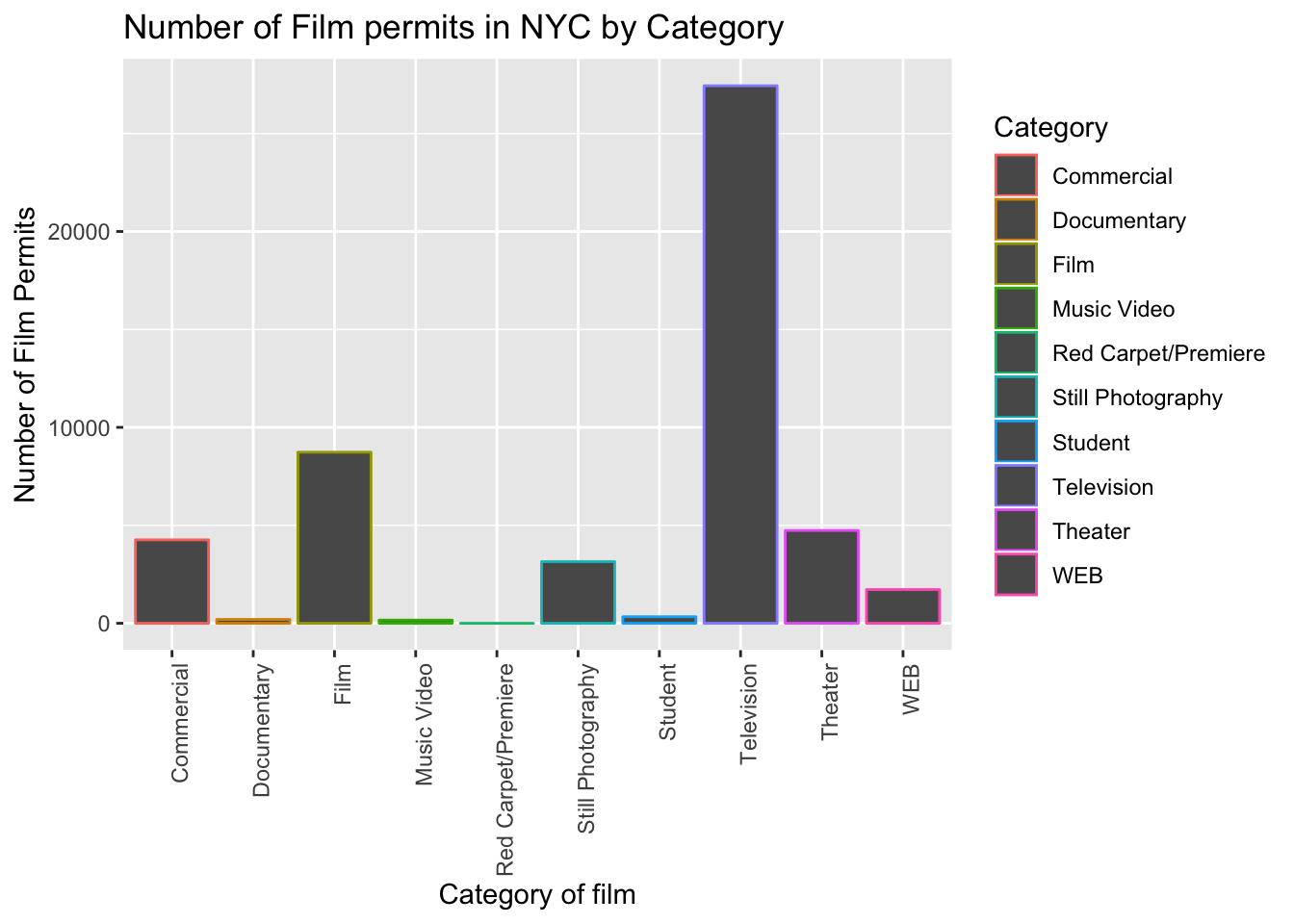
1.2.5.5 fill fills in color
Let’s make the bars different colors. To do this, we add new code to the inside of the aes() part…Notice I’ve started using new lines to make the code more readable.
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category")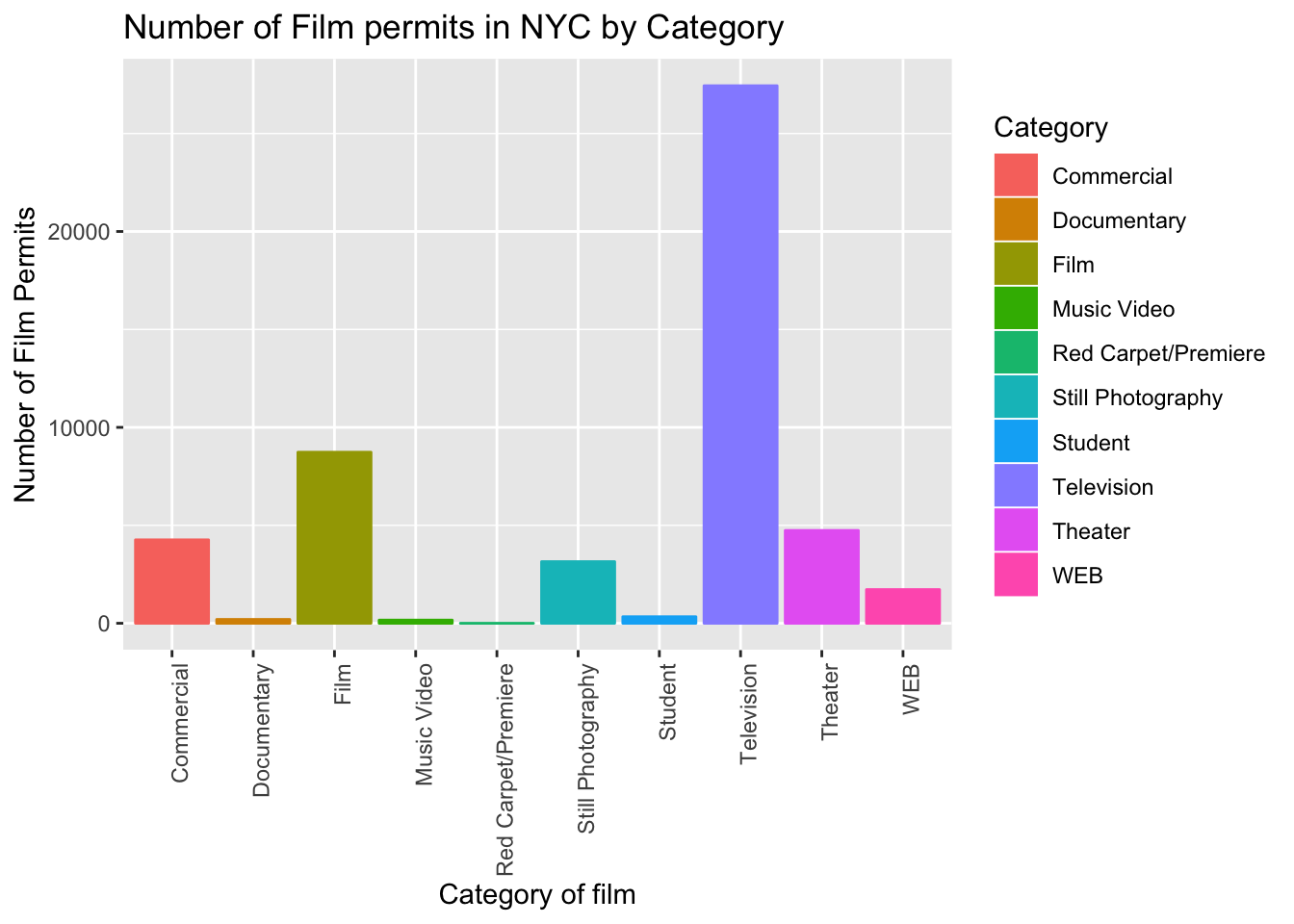
1.2.5.6 get rid of the legend
Sometimes you just don’t want the legend on the side, to remove it add
theme(legend.position="none")
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category") +
theme(legend.position="none")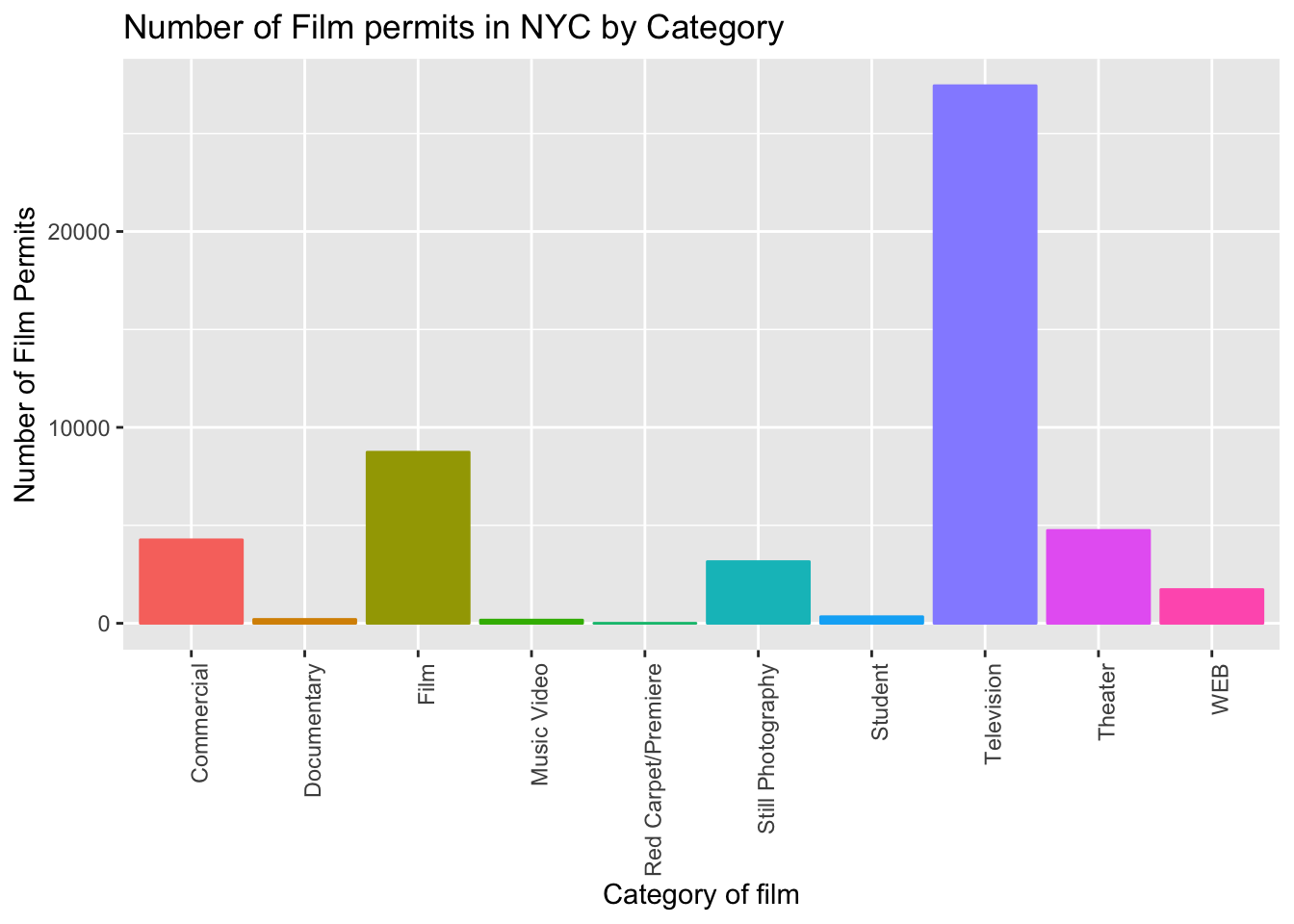
1.2.5.7 theme_classic() makes white background
The rest is often just visual preference. For example, the graph above has this grey grid behind the bars. For a clean classic no nonsense look, use theme_classic() to take away the grid.
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category") +
theme(legend.position="none") +
theme_classic()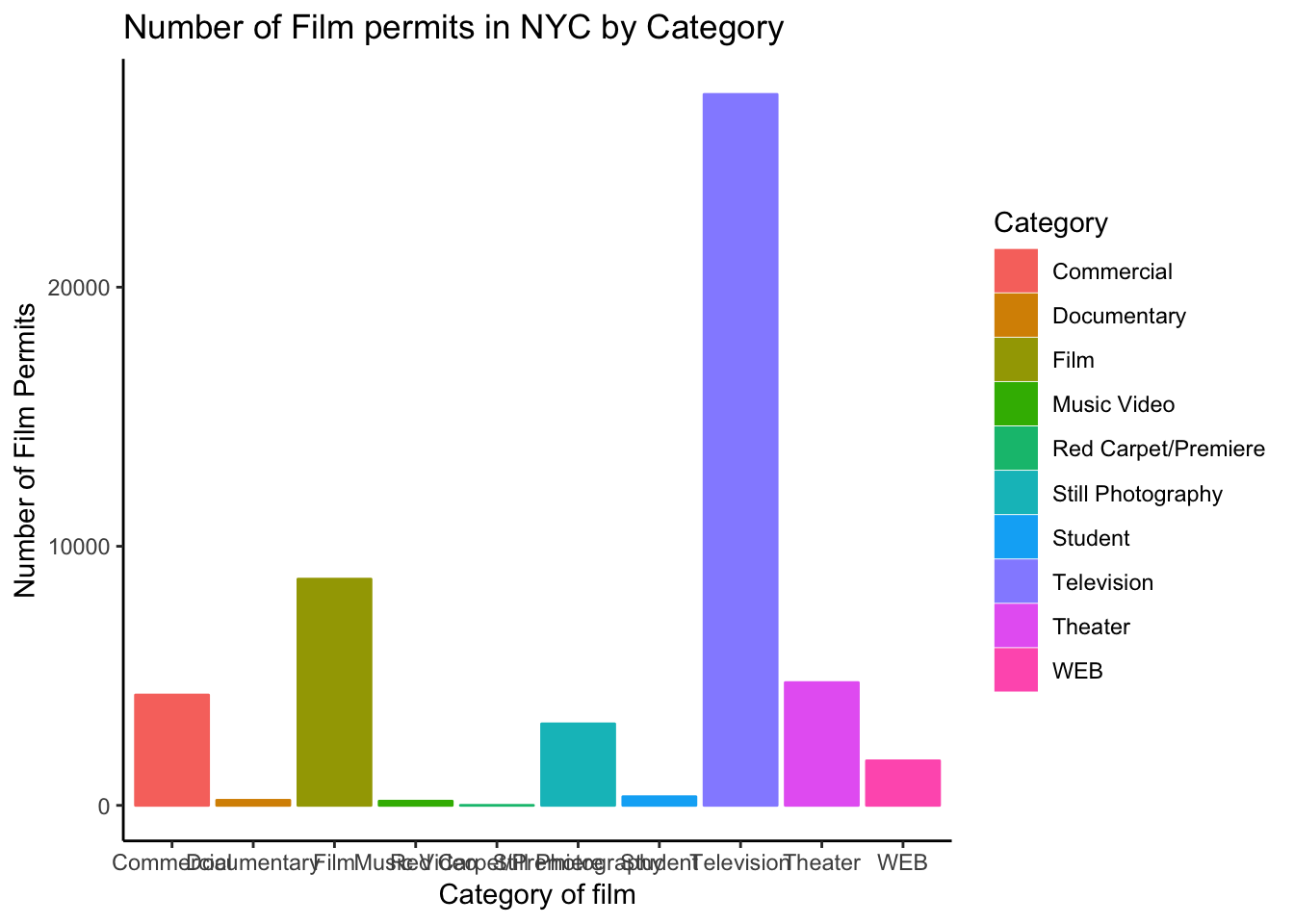
1.2.5.8 Sometimes layer order matters
Interesting, theme_classic() is misbehaving a little bit. It looks like we have some of our layer out of order, let’s re-order. I just moved theme_classic() to just underneath the geom_bar() line. Now everything get’s drawn properly.
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme_classic() +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category") +
theme(legend.position="none") 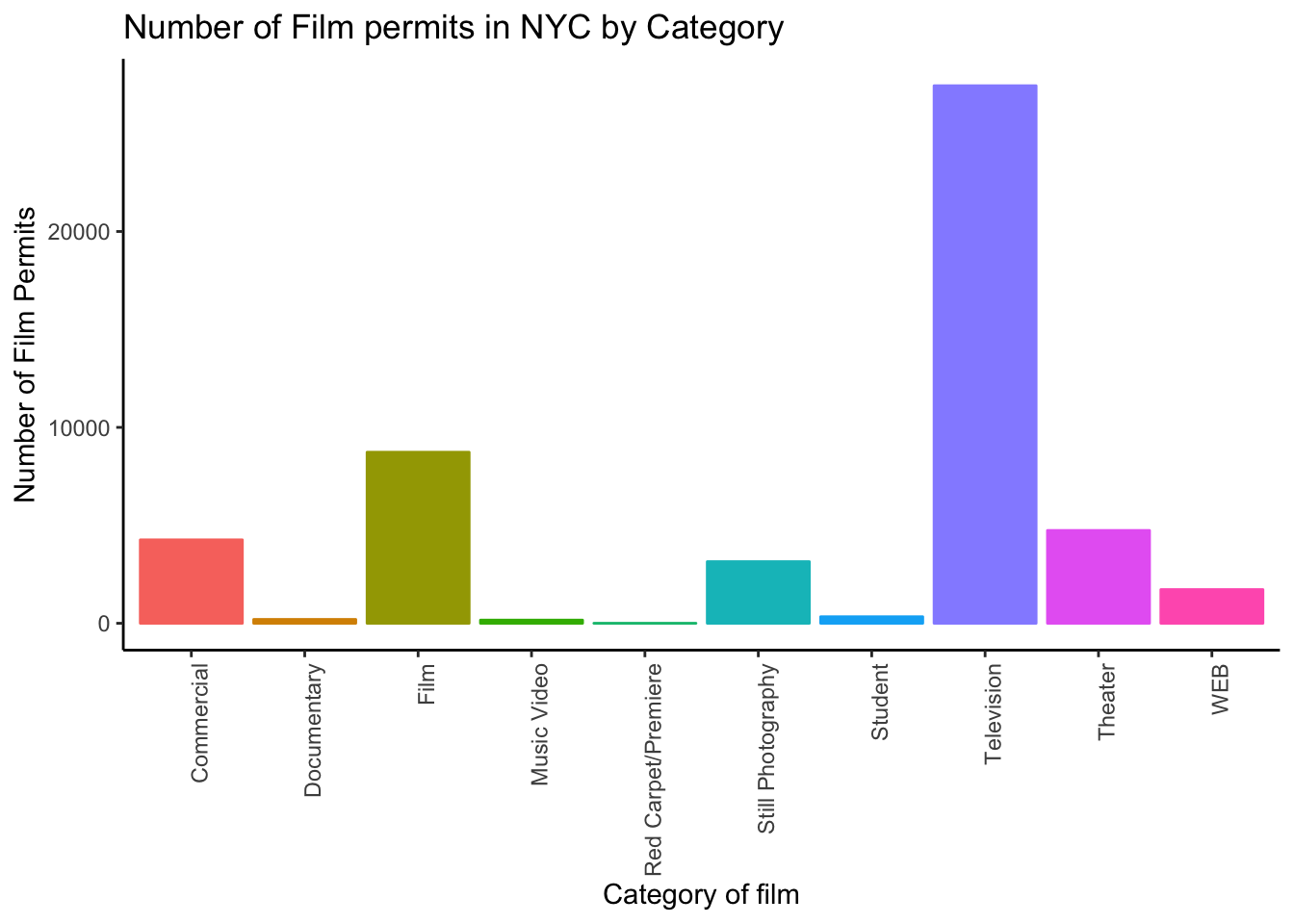
1.2.5.9 Font-size
Changing font-size is often something you want to do. ggplot2 can do this in different ways. I suggest using the base_size option inside theme_classic(). You set one number for the largest font size in the graph, and everything else gets scaled to fit with that that first number. It’s really convenient. Look for the inside of theme_classic()
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme_classic(base_size = 15) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category") +
theme(legend.position="none") 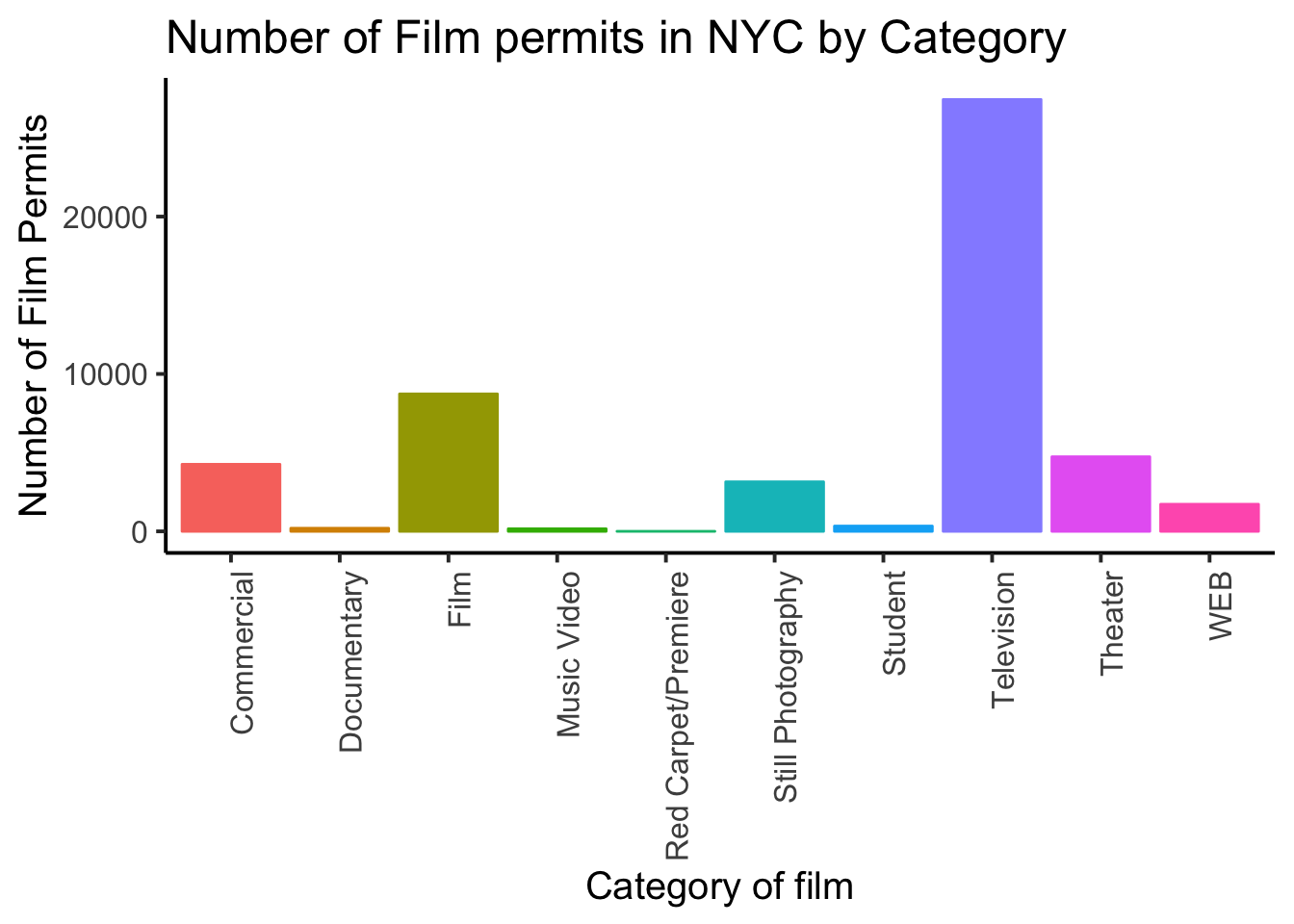 or make things small… just to see what happens
or make things small… just to see what happens
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme_classic(base_size = 10) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category") +
theme(legend.position="none") 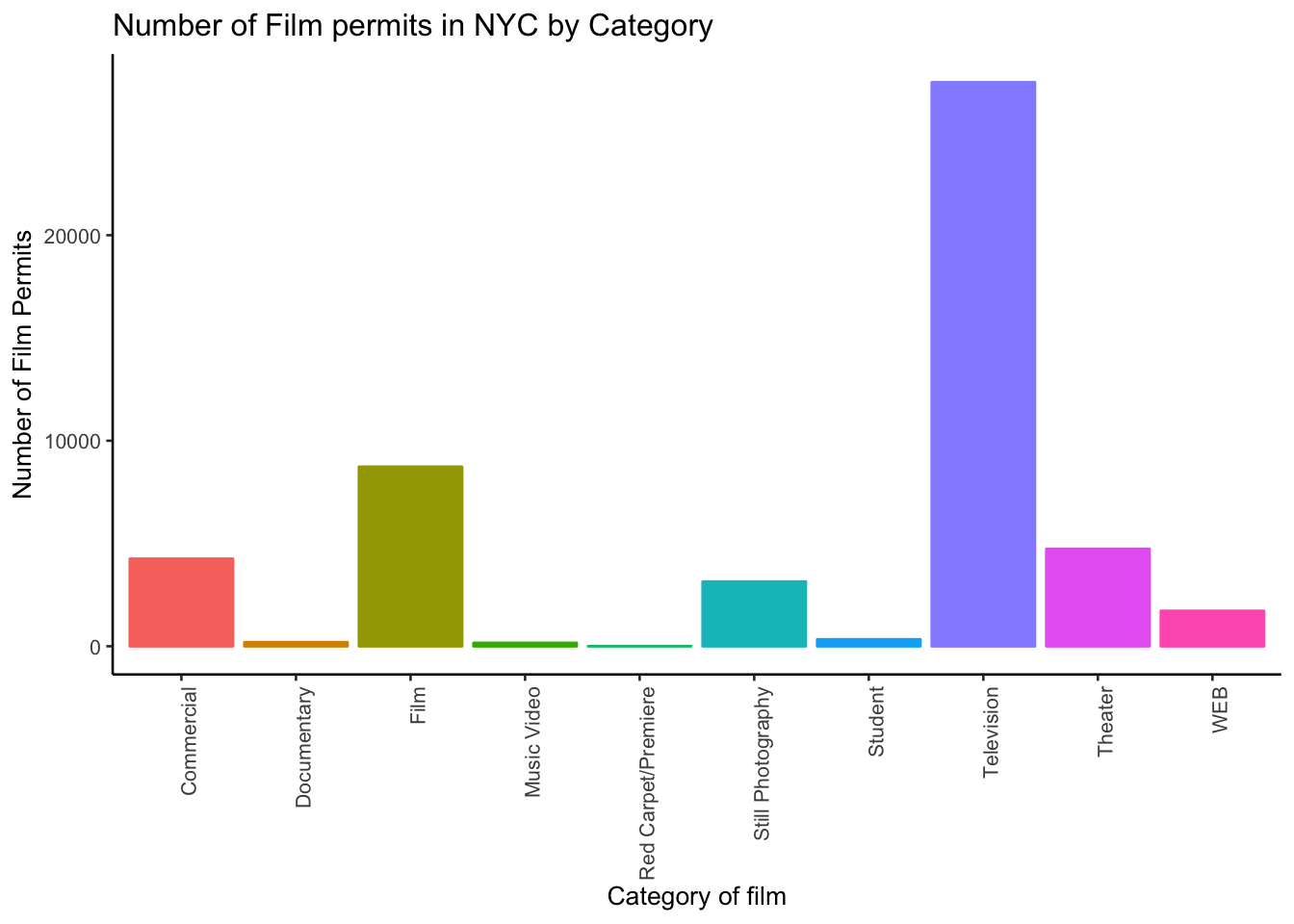
1.2.5.10 ggplot2 summary
That’s enough of the ggplot2 basics for now. You will discover that many things are possible with ggplot2. It is amazing. We are going to get back to answering some questions about the data with graphs. But, now that we have built the code to make the graphs, all we need to do is copy-paste, and make a few small changes, and boom, we have our graph.
1.2.6 More questions about NYC films
1.2.6.1 What are the sub-categories of films?
Notice the nyc_films data frame also has a column for SubCategoryName. Let’s see what’s going on there with a quick plot.
# get the counts (this is a comment it's just here for you to read)
counts <- nyc_films %>%
group_by(SubCategoryName) %>%
summarize(count_of_permits = length(SubCategoryName))
# make the plot
ggplot(counts, aes(x = SubCategoryName, y = count_of_permits,
color=SubCategoryName,
fill= SubCategoryName )) +
geom_bar(stat="identity") +
theme_classic(base_size = 10) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Sub-category of film") +
ggtitle("Number of Film permits in NYC by Sub-category") +
theme(legend.position="none") 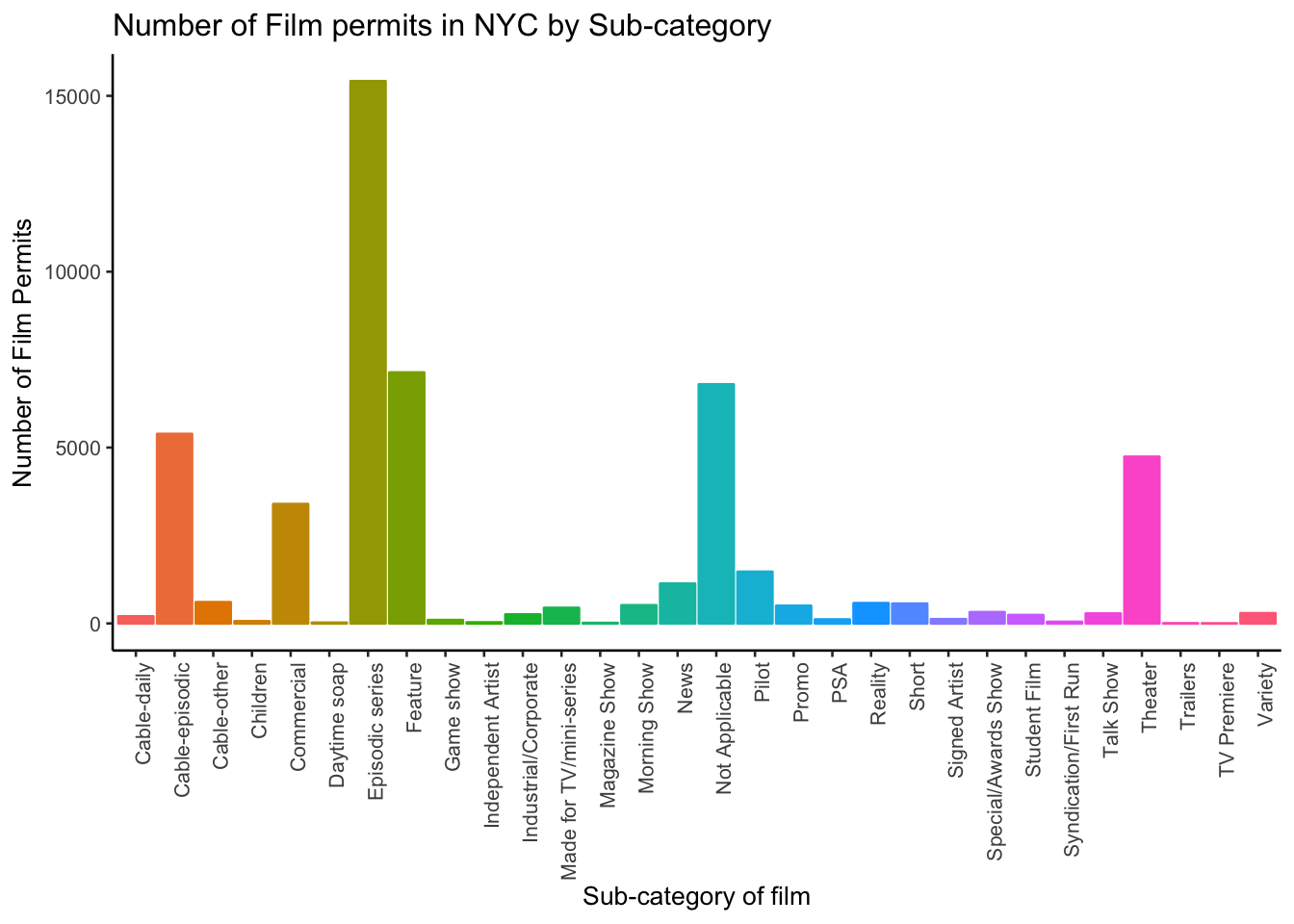
I guess “episodic series” are the most common. Using a graph like this gave us our answer super fast.
1.2.6.2 Categories by different Boroughs
Let’s see one more really useful thing about ggplot2. It’s called facet_wrap(). It’s an ugly word, but you will see that it is very cool, and you can do next-level-super-hero graph styles with facet_wrap that other people can’t do very easily.
Here’s our question. We know that some films are made in different Boroughs, and that same films are made in different categories, but do different Boroughs have different patterns for the kinds of categories of films they request permits for? Are their more TV shows in Brooklyn? How do we find out? Watch, just like this:
# get the counts (this is a comment it's just here for you to read)
counts <- nyc_films %>%
group_by(Borough,Category) %>%
summarize(count_of_permits = length(Category))
# make the plot
ggplot(counts, aes(x = Category, y = count_of_permits,
color=Category,
fill= Category )) +
geom_bar(stat="identity") +
theme_classic(base_size = 10) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Category of film") +
ggtitle("Number of Film permits in NYC by Category and Borough") +
theme(legend.position="none") +
facet_wrap(~Borough, ncol=3)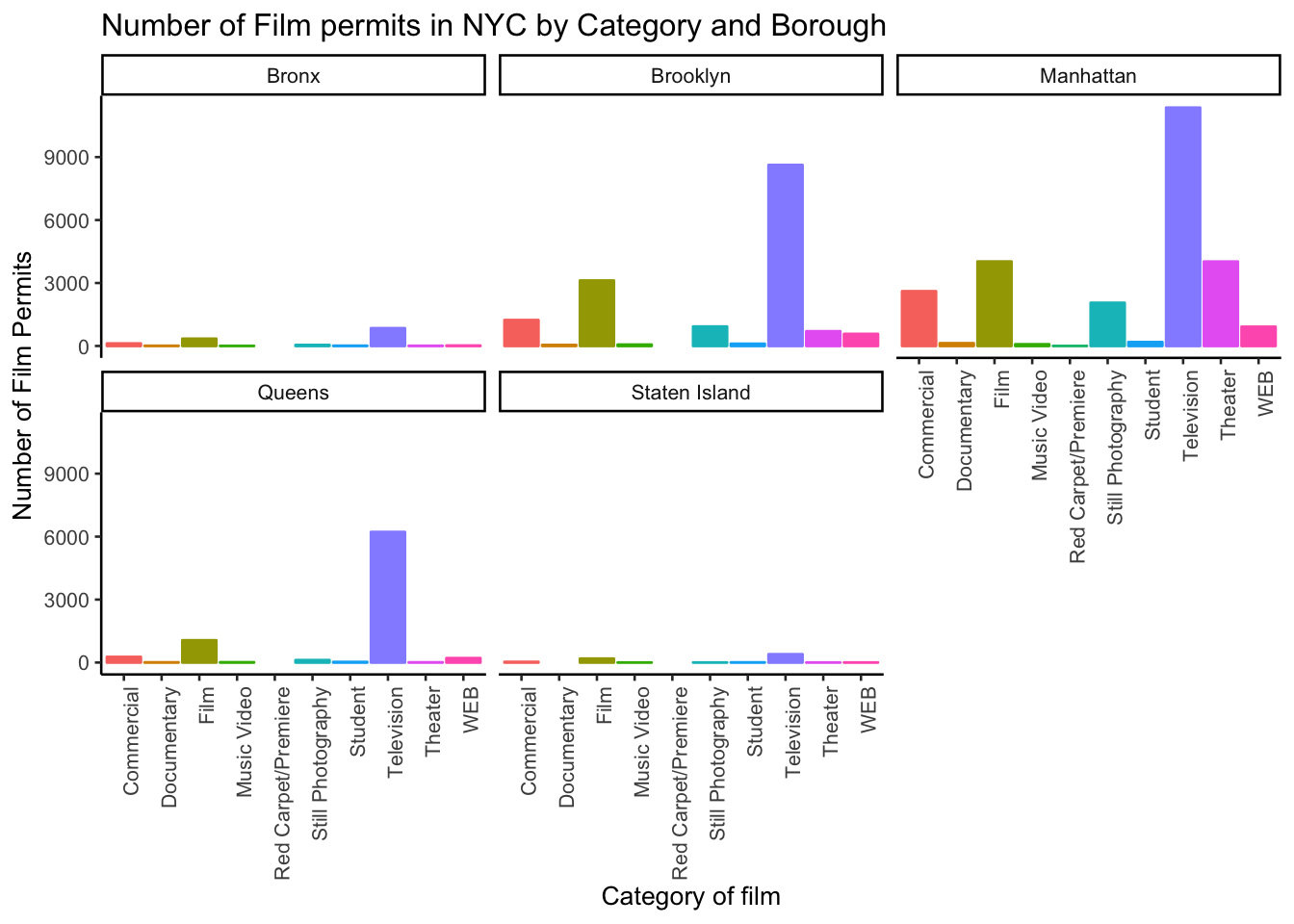
We did two important things. First we added Borough and Category into the group_by() function. This automatically gives separate counts for each category of film, for each Borough. Then we added facet_wrap(~Borough, ncol=3) to the end of the plot, and it automatically drew us 5 different bar graphs, one for each Borough! That was fast. Imagine doing that by hand.
The nice thing about this is we can switch things around if we want. For example, we could do it this way by switching the Category with Borough, and facet-wrapping by Category instead of Borough like we did above. Do what works for you.
ggplot(counts, aes(x = Borough, y = count_of_permits,
color=Borough,
fill= Borough )) +
geom_bar(stat="identity") +
theme_classic(base_size = 10) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
ylab("Number of Film Permits") +
xlab("Borough") +
ggtitle("Number of Film permits in NYC by Category and Borough") +
theme(legend.position="none") +
facet_wrap(~Category, ncol=5)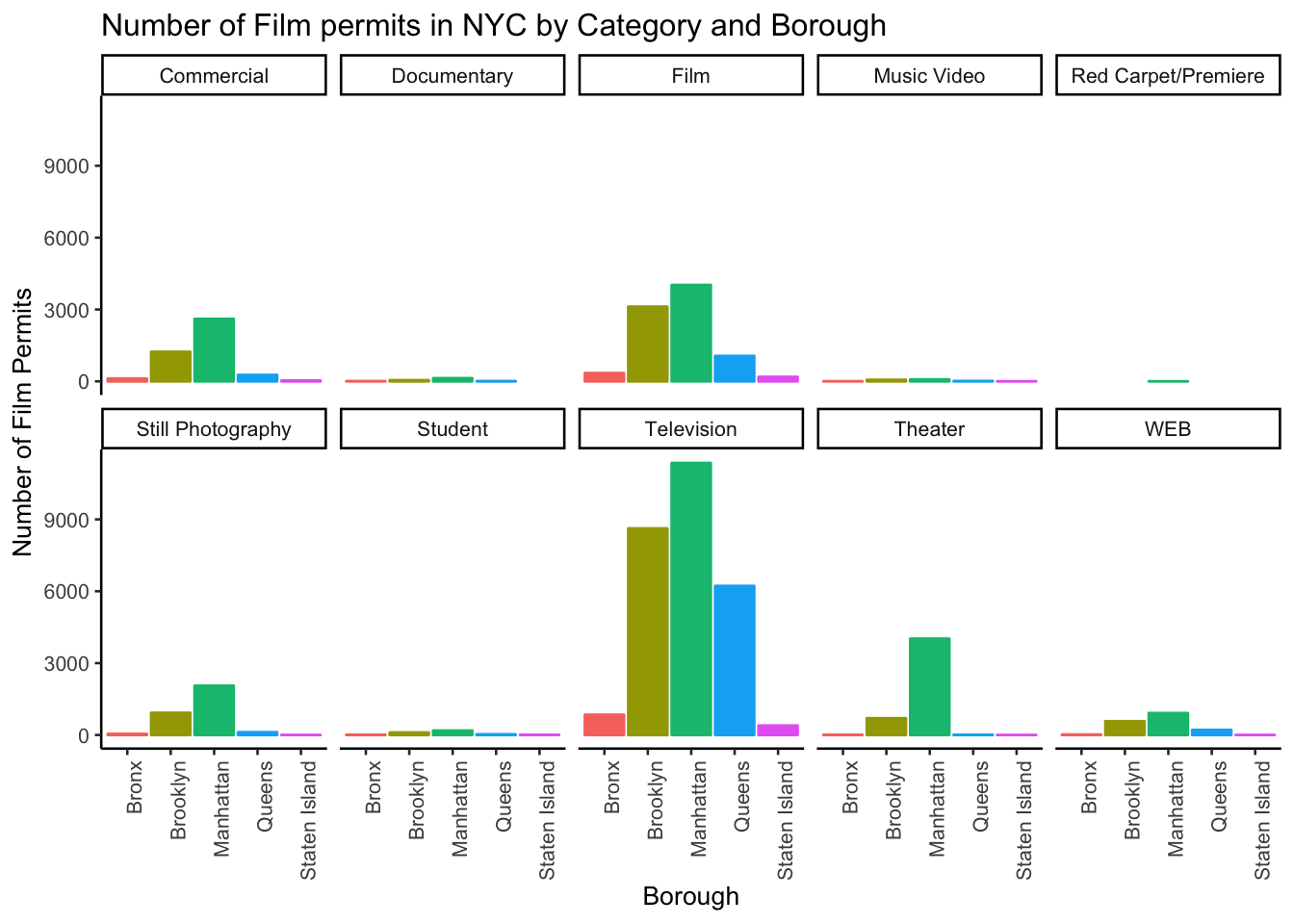
1.2.7 Gapminder Data
https://www.gapminder.org is an organization that collects some really interesting worldwide data. They also make cool visualization tools for looking at the data. There are many neat examples, and they have visualization tools built right into their website that you can play around with https://www.gapminder.org/tools/. That’s fun check it out.
There is also an R package called gapminder. When you install this package, it loads in some of the data from gapminder, so we can play with it in R.
If you don’t have the gapminder package installed, you can install it by running this code
install.packages("gapminder")Once the package is installed, you need to load the new library, like this. Then, you can put the gapminder data into a data frame, like we do here: gapminder_df.
library(gapminder)
gapminder_df<-gapminder1.2.7.1 Look at the data frame
You can look at the data frame to see what is in it, and you can use summarytools again to view a summary of the data.
view(dfSummary(gapminder_df))There are 1704 rows of data, and we see some columns for country, continent, year, life expectancy, population, and GDP per capita.
1.2.8 Asking Questions with the gap minder data
We will show you how to graph some the data to answer a few different kinds of questions. Then you will form your own questions, and see if you can answer them with ggplot2 yourself. All you will need to do is copy and paste the following examples, and change them up a little bit
1.2.8.1 Life Expectancy histogram
How long are people living all around the world according to this data set? There are many ways we could plot the data to find out. The first way is a histogram. We have many numbers for life expectancy in the column lifeExp. This is a big sample, full of numbers for 142 countries across many years. It’s easy to make a histogram in ggplot to view the distribution:
ggplot(gapminder_df, aes(x=lifeExp))+
geom_histogram(color="white")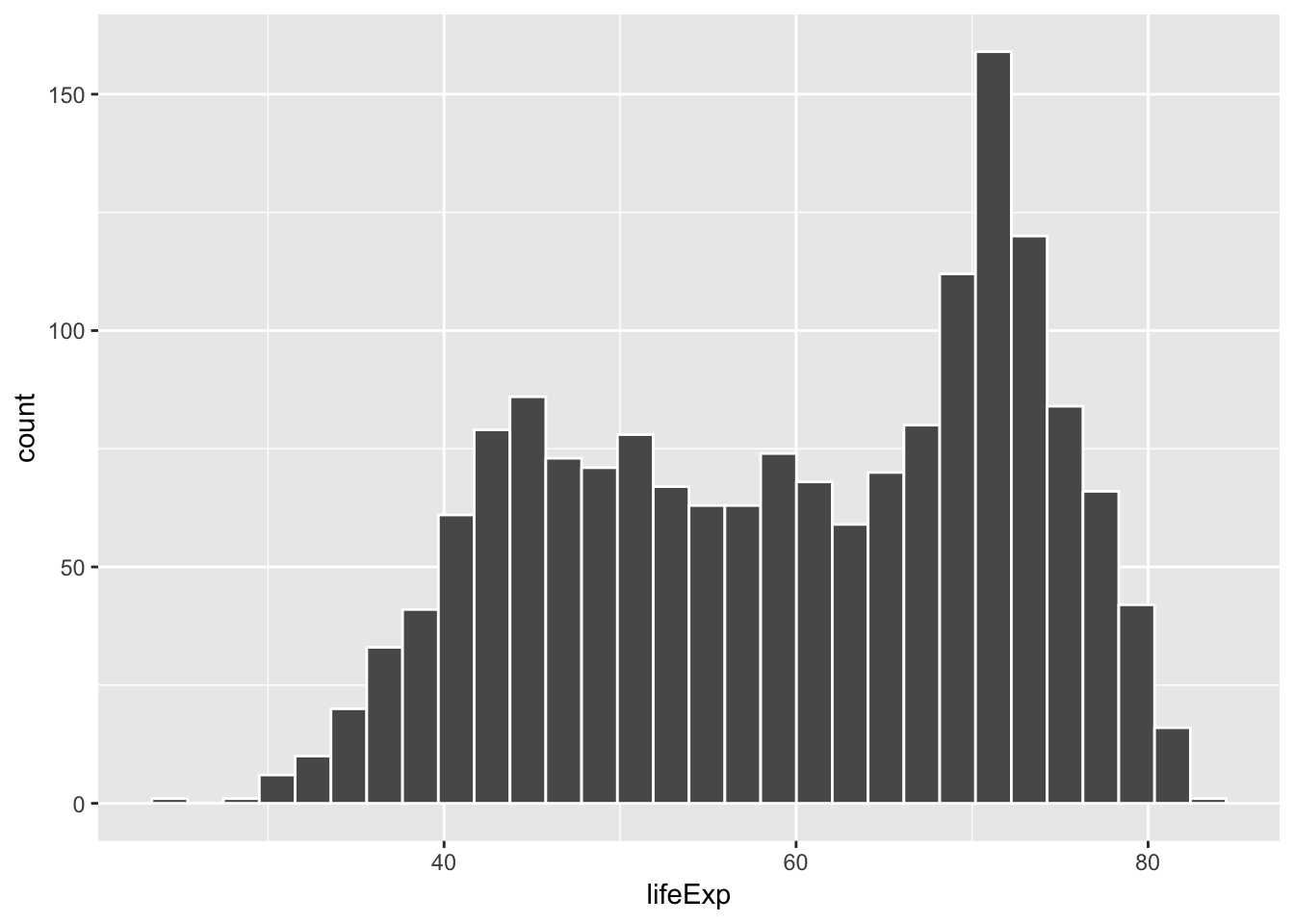
See, that was easy. Next, is a code block that adds more layers and settings if you wanted to modify parts of the graph:
ggplot(gapminder_df, aes(x = lifeExp)) +
geom_histogram(color="white")+
theme_classic(base_size = 15) +
ylab("Frequency count") +
xlab("Life Expectancy") +
ggtitle("Histogram of Life Expectancy from Gapminder")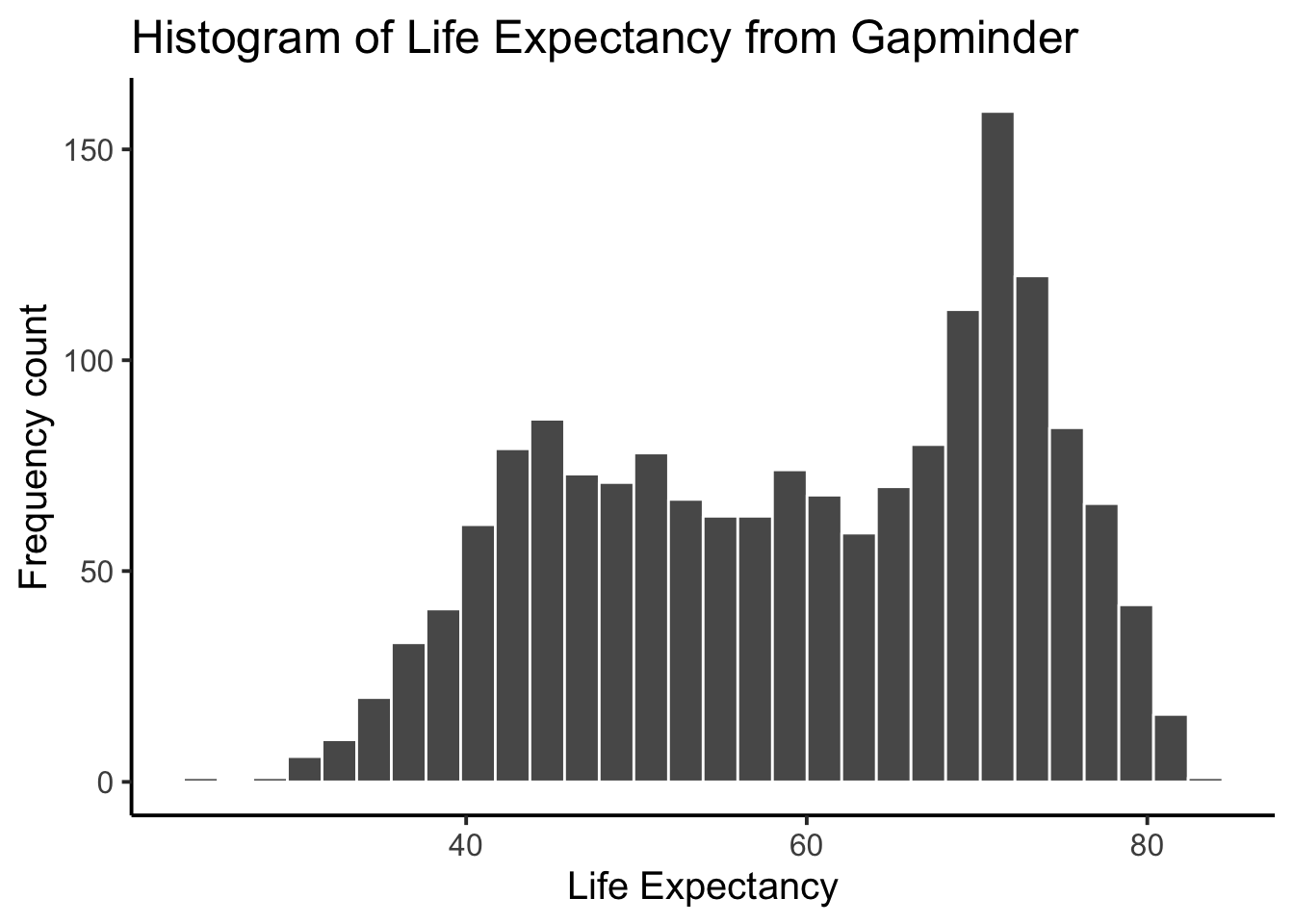
The histogram shows a wide range of life expectancies, from below 40 to just over 80. Histograms are useful, they can show you what kinds of values happen more often than others.
One final thing about histograms in ggplot. You may want to change the bin size. That controls how wide or narrow, or the number of bars (how they split across the range), in the histogram. You need to set the bins= option in geom_histogram().
ggplot(gapminder_df, aes(x = lifeExp)) +
geom_histogram(color="white", bins=50)+
theme_classic(base_size = 15) +
ylab("Frequency count") +
xlab("Life Expectancy") +
ggtitle("Histogram of Life Expectancy from Gapminder")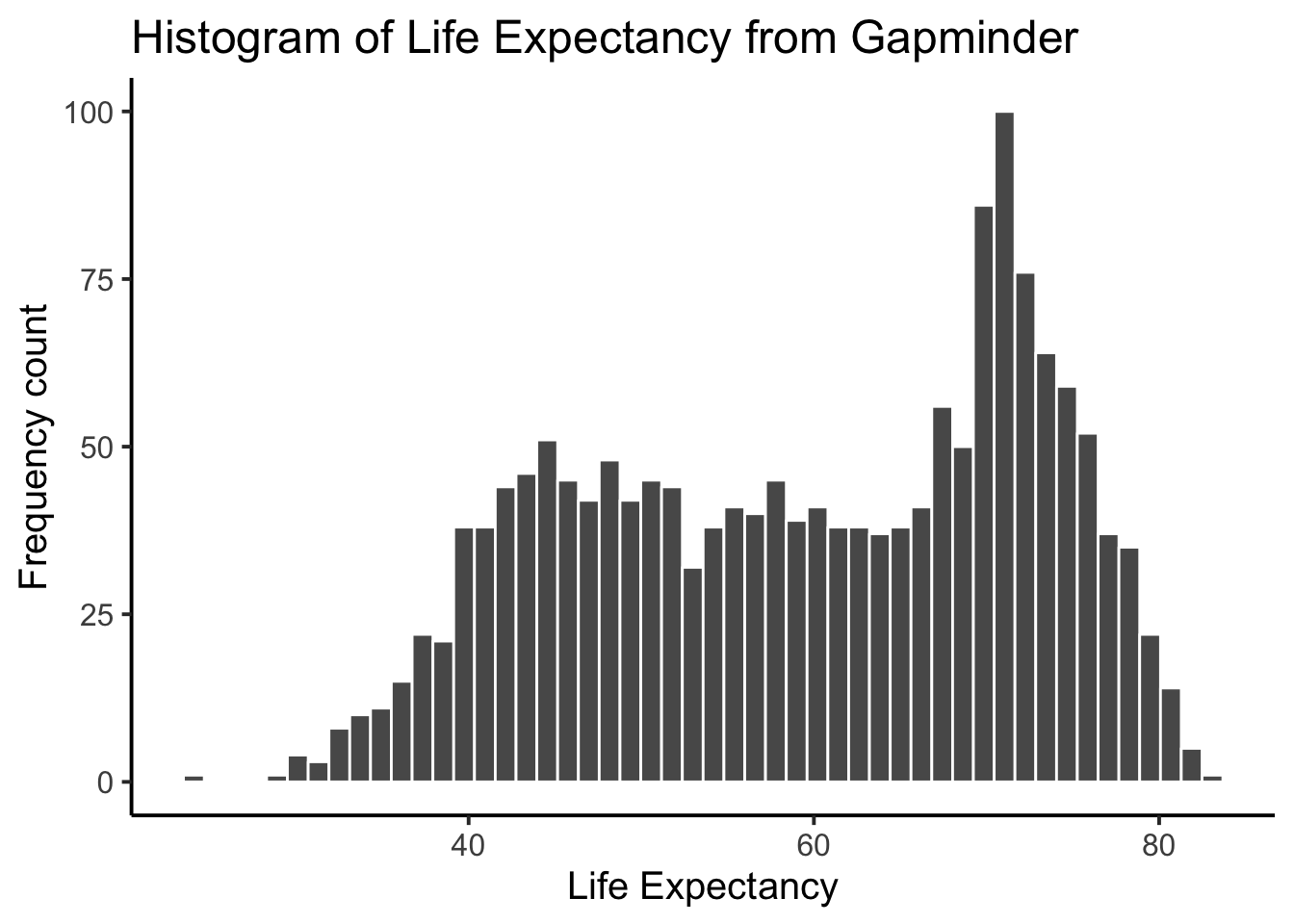
See, same basic patter, but now breaking up the range into 50 little equal sized bins, rather than 30, which is the default. You get to choose what you want to do.
1.2.8.2 Life Expectancy by year Scatterplot
We can see we have data for life expectancy and different years. So, does worldwide life expectancy change across the years in the data set? As we go into the future, are people living longer?
Let’s look at this using a scatter plot. We can set the x-axis to be year, and the y-axis to be life expectancy. Then we can use geom_point() to display a whole bunch of dots, and then look at them. Here’s the simple code:
ggplot(gapminder_df, aes(y= lifeExp, x= year))+
geom_point()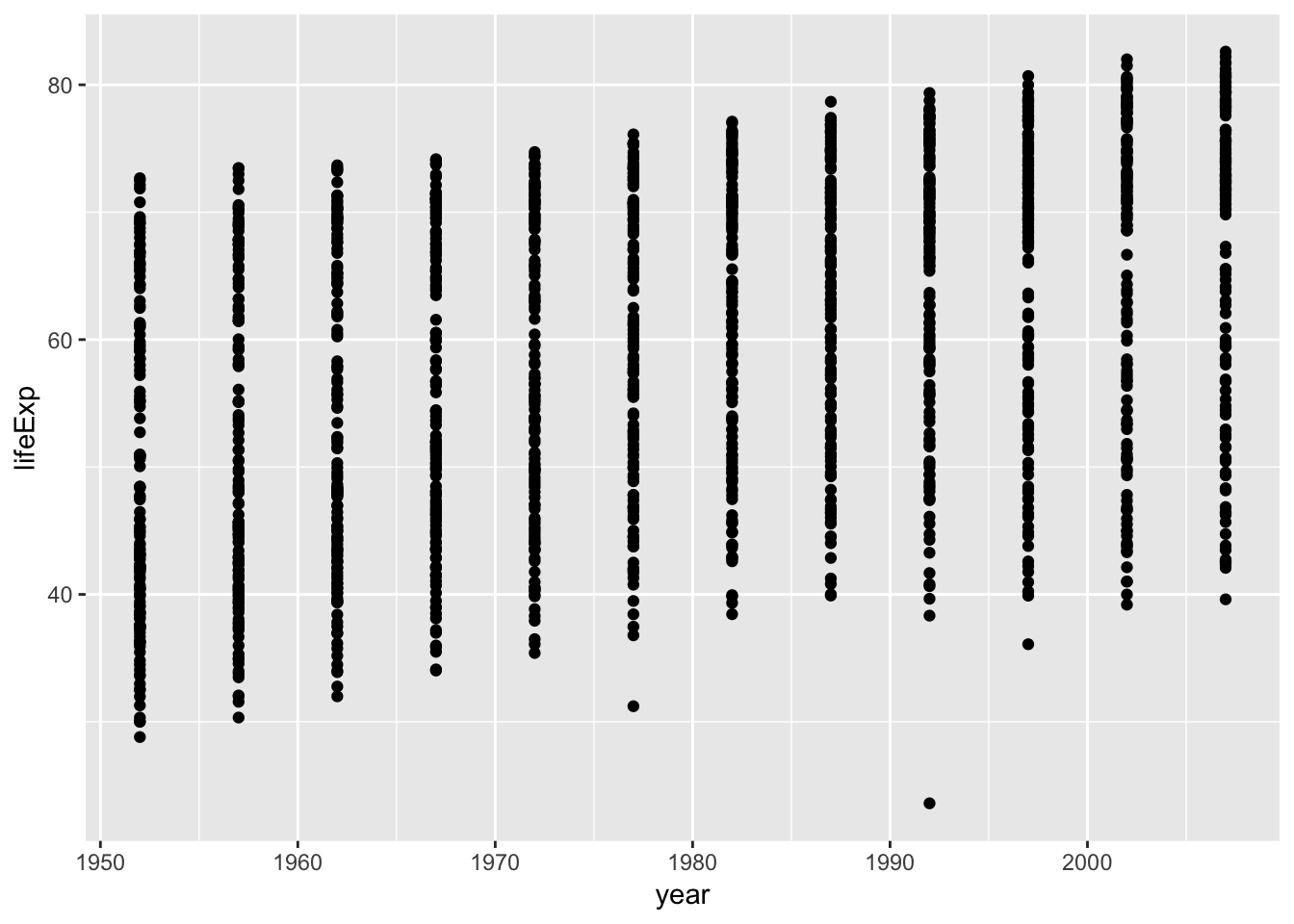
Whoa, that’s a lot of dots! Remember that each country is measured each year. So, the bands of dots you see, show the life expectancies for the whole range of countries within each year of the database. There is a big spread inside each year. But, on the whole it looks like groups of dots slowly go up over years.
1.2.8.3 One country, life expectancy by year
I’m (Matt) from Canada, so maybe I want to know if life expectancy for Canadians is going up over the years. To find out the answer for one country, we first need to split the full data set, into another smaller data set that only contains data for Canada. In other words, we want only the rows where the word “Canada” is found in the country column. We will use the filter function from dplyr for this:
# filter rows to contain Canada
smaller_df <- gapminder_df %>%
filter(country == "Canada")
# plot the new data contained in smaller_df
ggplot(smaller_df, aes(y= lifeExp, x= year))+
geom_point()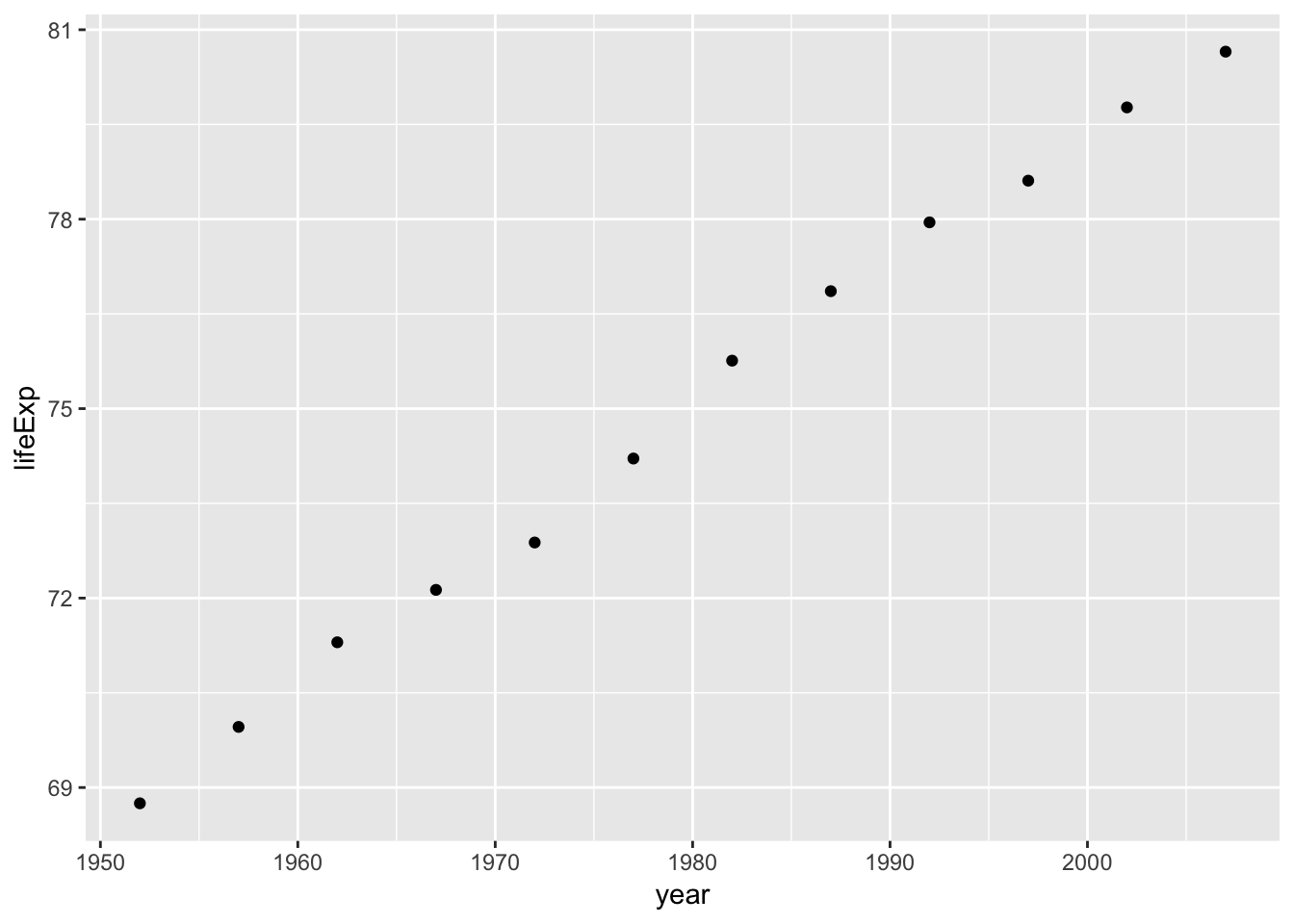
I would say things are looking good for Canadians, their life expectancy is going up over the years!
1.2.8.4 Multiple countries scatterplot
What if we want to look at a few countries altogether. We can do this too. We just change how we filter the data so more than one country is allowed, then we plot the data. We will also add some nicer color options and make the plot look pretty. First, the simple code:
# filter rows to contain countries of choice
smaller_df <- gapminder_df %>%
filter(country %in% c("Canada","France","Brazil") == TRUE)
# plot the new data contained in smaller_df
ggplot(smaller_df, aes(y= lifeExp, x= year, group= country))+
geom_point()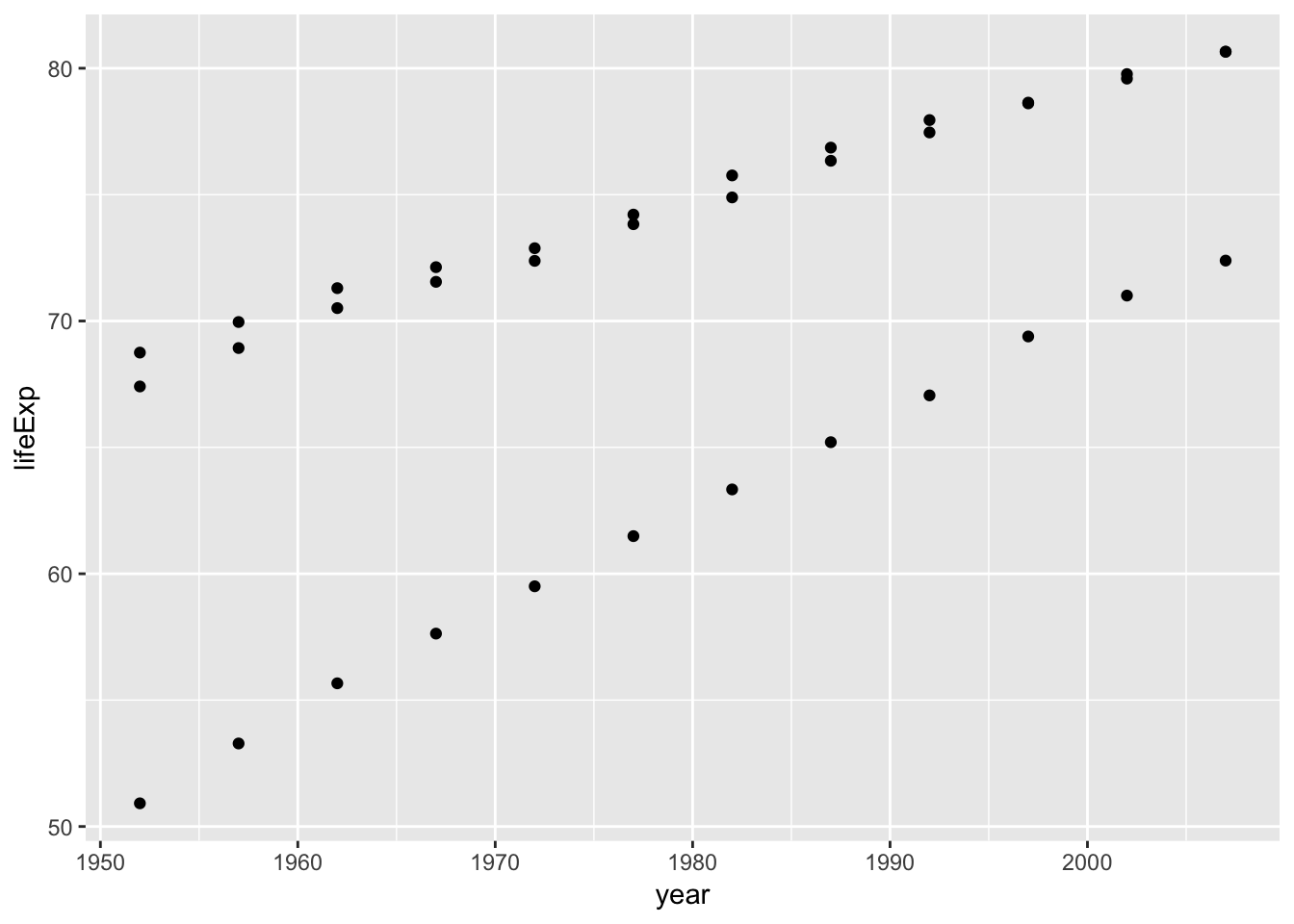
Nice, we can now see three sets of dots, but which are countries do they represent? Let’s add a legend, and make the graph better looking.
ggplot(smaller_df,aes(y= lifeExp, x= year,
group= country, color = country)) +
geom_point()+
theme_classic(base_size = 15) +
ylab("Life Expectancy") +
xlab("Year") +
ggtitle("Life expectancy by year for three countries")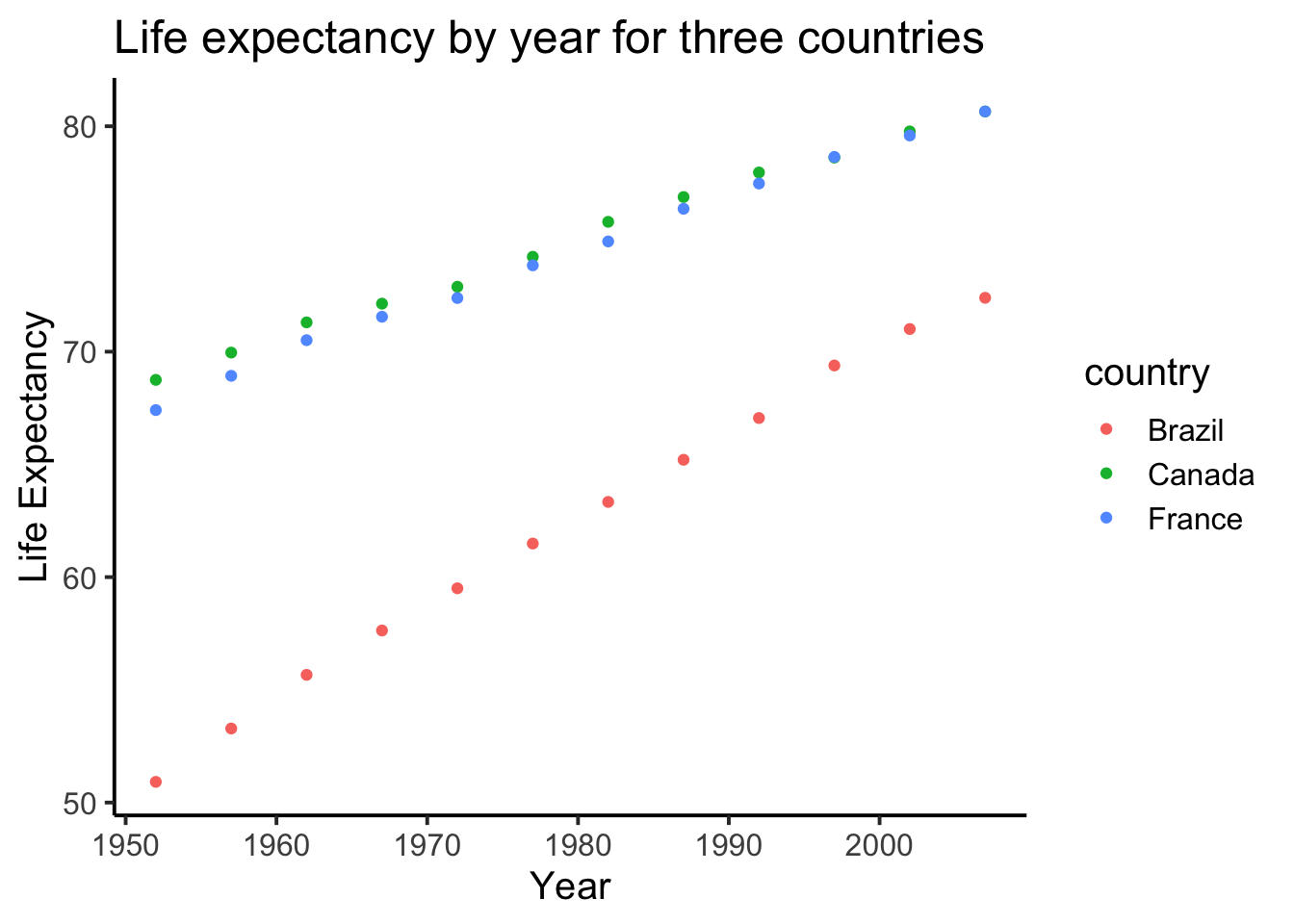
1.2.8.5 geom_line() connecting the dots
We might also want to connect the dots with a line, to make it easier to see the connection! Remember, ggplot2 draws layers on top of layers. So, we add in a new geom_line() layer.
ggplot(smaller_df,aes(y= lifeExp, x= year,
group= country, color = country)) +
geom_point()+
geom_line()+
theme_classic(base_size = 15) +
ylab("Life Expectancy") +
xlab("Year") +
ggtitle("Life expectancy by year for three countries")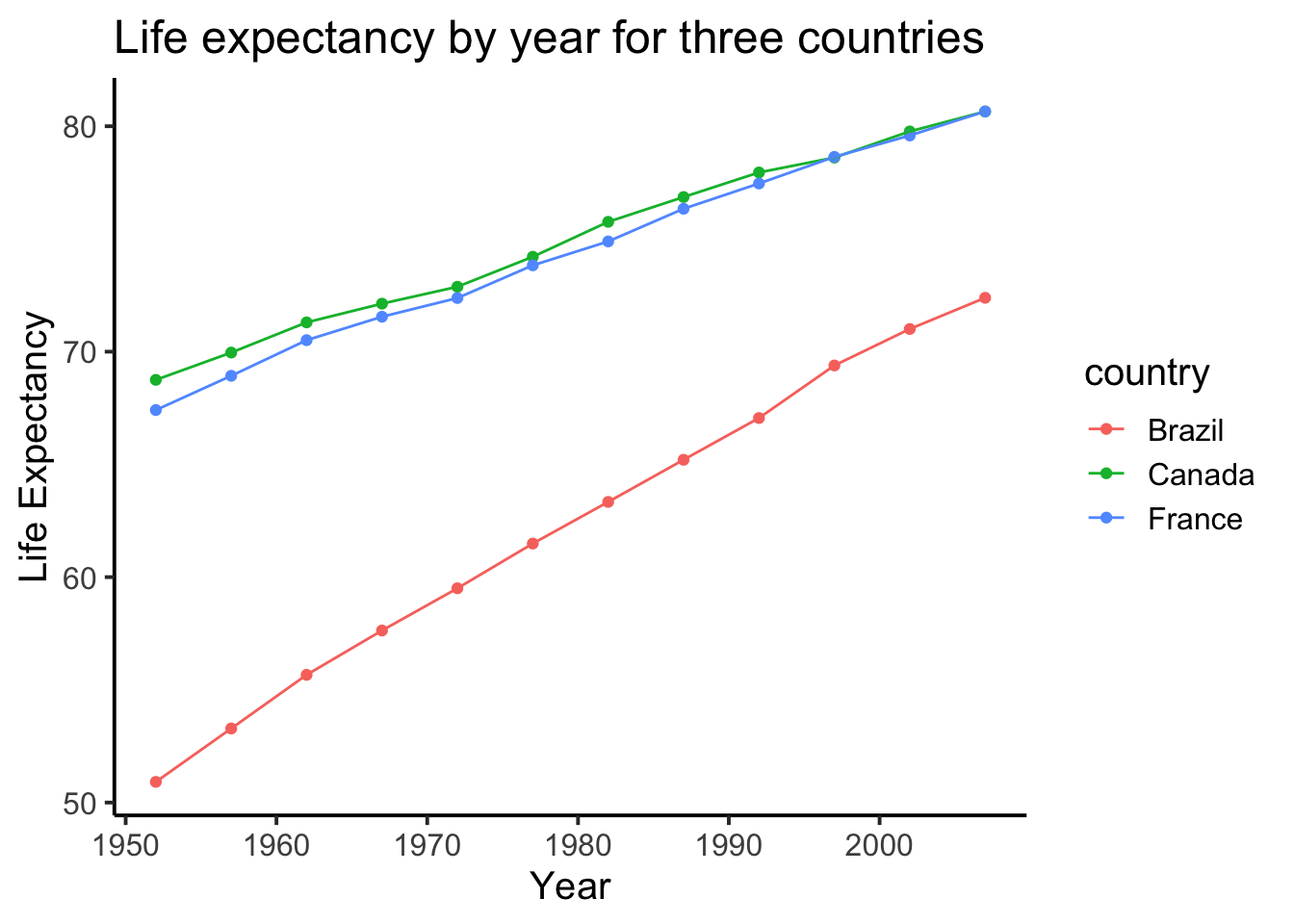
1.2.9 Generalization Exercise
The following generalization exercise and writing assignment is also in your lab R Markdown document for this lab. Complete your work in that document and hand it in.
(1 point - Pass/Fail)
Use the code from above to attempt to solve the extra things we ask you do for this assignment. You generalization exercises are as follows:
Make a graph plotting Life Expectancy by year for the five continents, using the
continentfactor. Make sure you change the title so it reads correctlyMake a graph plotting GDP per capita by year for the USA, Canada, and Mexico. Use the
gdpPercapcolumn for the GDP per capita dataMake a new graph plotting anything you are interested in using the gapminder dataset. It just needs to be a plot that we have not given an example for
1.2.10 Writing assignment
Complete the writing assignment described in your R Markdown document for this lab. When you have finished everything. Knit the document and hand in your stuff (you can submit your .RMD file to blackboard if it does not knit.)
The question for this lab is a long answer question about histograms. Here is the question:
Describe what histograms are, how to interpret them, and what they are useful for. You should answer each of these questions:
The answers to each of these questions are worth .25 points each, for a total of 2 points
- What do the bars on a histogram represent?
- How many bars can a histogram have?
- What do the heights of the bars tell you
- What is on the x-axis and y-axis of a histogram
- What does the tallest bar on a histogram tell you?
- What does the shortest bar on a histogram tell you?
- What are some uses for histograms, why would you want to look at a histogram of some numbers that you collected?
- Imagine you had two histograms, one was very wide and spread out, the other was very narrow with a very tall peak. Which histogram would you expect to contain more consistent numbers (numbers that are close to each other), explain why.
Rubric
General grading.
- You will receive 0 points for missing answers (say, if you do not answer question c, then you will receive 0 out .25 points for that question)
- You must write in complete sentences. Point form sentences will be given 0 points.
- Completely incorrect answers will receive 0 points. For example, if you incorrectly describe what the x and y-axes refer to, then you will receive 0 points for that question.
- If your answer is generally correct but very difficult to understand and unclear you may receive half points for the question
1.3 Excel
1.4 SPSS
In this lab, we will get you acquainted with the SPSS software layout and graph some sample data to make sense of it. We will be doing the following:
- Opening SPSS and the SPSS layout
- Reviewing variable properties and the Variable View tab
- Opening a data file and producing different types of graphs
1.4.1 Opening SPSS and the SPSS layout
Your lab instructor will take you through the process of opening the SPSS program. You may double-click on its icon located on the desktop of your lab computer, or you may find it using the Start menu. Once the program loads, you will be prompted with a pop-up window that asks you which file you would like to open. For now, we will be examining the basic layout of SPSS without a data set, so you can click Cancel.
Once you do, the main SPSS spreadsheet should open. It will look like this, a basic spreadsheet:
Figure 1.1: Empty SPSS spreadsheet
Notice at the bottom of your window there are two tabs; “Data View” and “Variable View”. In data view, we enter data into our spreadsheet. You will notice that rows are numbered on the left-hand side of the spreadsheet, while columns are labeled “var”. This is an indication of the general structure of SPSS: Variables are contained in the columns, and rows indicate individual observations. For example, if you obtained the heights (in inches) of 5 people {x= 64, 70, 63, 62, 65} and wanted to enter their data into SPSS, each person’s height would be entered in a new row, not across the columns, as seen below:
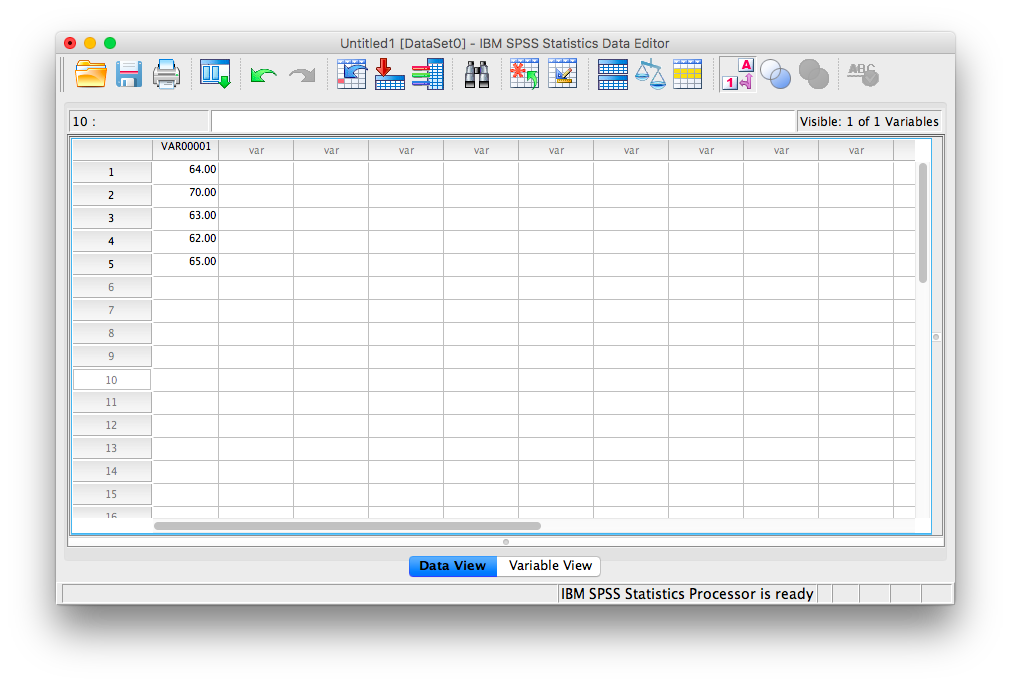
1.4.2 Reviewing variable properties and the Variable View tab
Now that we have some data entered, we might want to name our variable so that it’s evident our measurements represent heights. In order o view or modify variable names and other properties, look to the bottom of your SPSS window and switch over to the “Data View” tab. Once you do this, your window will appear as follows:
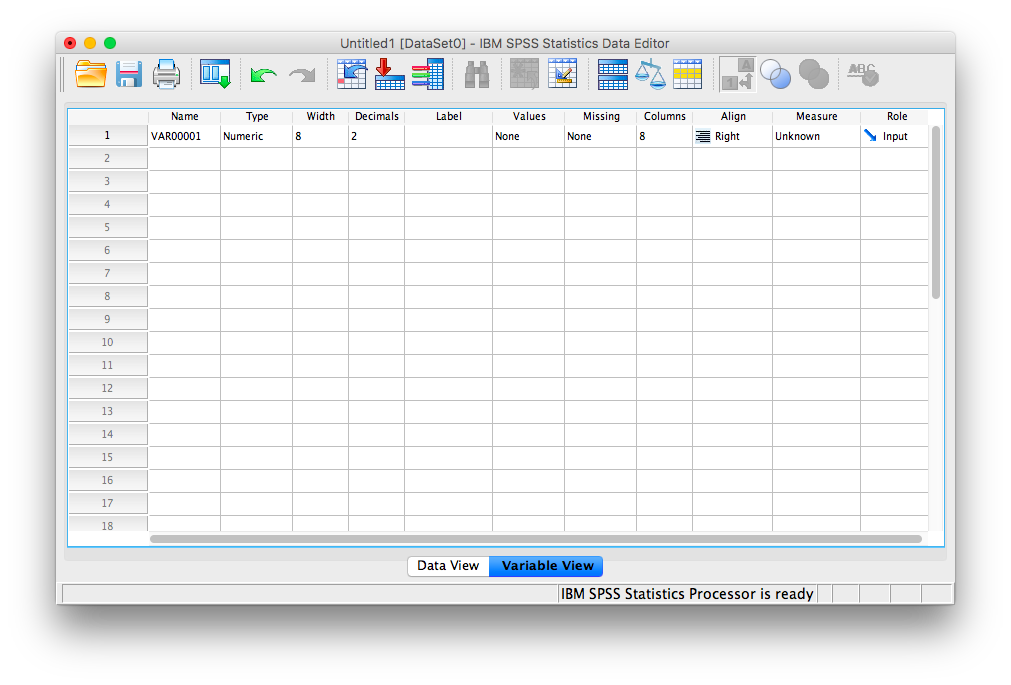
Here, you can edit the name of your variables, and specify their properties. Variable names can be anything you like, with the restriction that you cannot use numbers or spaces. Next, notice several other important properties of variables you may at some point need to set or modify:
- Name: the name of your variable that will appear as a colum header in Data View. No spaces or numerals.
- Type: Your data will most often be Numeric, but sometimes, as in data representing currency or data in scientific notation, you may change the data type appropriately. If your data is simply a label, word, or response (such as an open-ended response to a survey question), choose “String”: this tells SPSS not to treat this variable as a number. (Nota bene: if you select the wrong type of variable, SPSS may not be able to process your requested calculations, so always remember to check this parameter!)
- Width: This refers to how many digits will be visible by default.
- Decimals: This refers to how many decimal places will be visible by default.
- Label: This is a description of the variable. Any information too long to be included in the variable name goes here.
- Values: For nominal scale data, let’s say 1 represents male and 2 represents female, this is where you include the values and their corresponding labels.
- Measure: This variable property allows you to specify the nature of your data. Depending on the kind of scale you are using, you will choose a different measure type. Nominal and ordinal are chosen for nominal and ordinal scales, respectively. “Scale” is used when your data is measured on a ratio or interval scale. (Nota bene: this “Measure” designation is only a marker; it does not affect the calculations as in the “Type” parameter. Even if you choose the wrong icon/label for “Measure”, SPSS will still produce the correct output)
1.4.3 Opening a data file and producing different types of graphs
Now that we know about the properties of the SPSS spreadsheet window, let’s open a data file and learn how to make some sense of it by creating different types of graphs. Here is a link to an SPSS-based data file containing information about film permits (requests made by film companies to shoot TV shows and movies on location) filed in New York City. The file is named nyc_films.sav.
Once you open the data file, browse through to familiarize yourself with the variables that are being measured. Switch over to Variable View for details of each variable.
1.4.3.1 Bar Graphs
Now, back to Data View. We will not be working with every single variable in this spreadsheet, but we’ll select a few interesting ones with which to answer questions. Let’s start with borough. Suppose we wanted to know which borough receives the most film permits (you can probably guess which one is most popular). Let’s use SPSS to produce a graph to answer this question. With your data file open, go up to the top menu and choose Graphs, then Legacy Dialogs. You will see an entire list of possible graphs we can use to plot our data.
Let’s think about the nature of our question: we would like to know how many permits were filed for each borough. Borough is simply a label or a name for a region, and we want to know the frequency of permits for each borough. This is a nominal scale variable and so, we will appropriately choose a BAR graph to plot it. Select Bar…
The next window will ask you to specify what kind of graph you would like. Select Simple and then Define.
 The following window will ask which variable you’d like to plot. Select
The following window will ask which variable you’d like to plot. Select borough from the left-hand list and use the arrow to move it into the field labeled “Category Axis”. Then click OK.
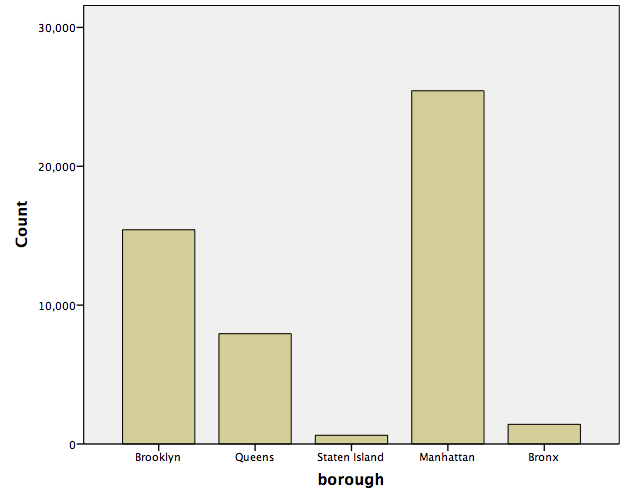
SPSS will produce a new output window which will contain the bar graph you have generated. Notice which borough receives the most film permits. Are you surprised?
1.4.3.2 Histograms
Now, let’s use a different data set to plot a histogram. The defining difference between a histogram and a bar graph (although they look very similar as they both utilize bars) is that a histogram is used to display a continuous variable (interval or ratio scale). In the previous example, boroughs were simply labels or names, so we used a nominal scale and therefore a bar graph. Here, we will deal with life expectancy (measured in years), an interval scale measure. Here is a link to the SPSS data file, life_expectancy.sav. Open this file and examine its rows and columns. Each column represents a year during which life expectancy was measured. Each row represents a different country.
Let’s first get an idea about life expectancy in general. We want to plot a histogram with life expectancy on the x-axis and frequency on the y-axis. Choose Graphs in the top menu, then Legacy Dialogs. From here, remember we want a histogram, not a bar graph, so let’s select Histogram….
The window that appears contains every variable in your spreadsheet listed on the left-hand side. We can choose one variable at a time to plot. Let’s scroll all the way down the list and choose 2017 [v219]. This is the variable containing life expectancies for the year 2017. Using the arrow, move that variable into the field labeled “Variable:”, then click OK.
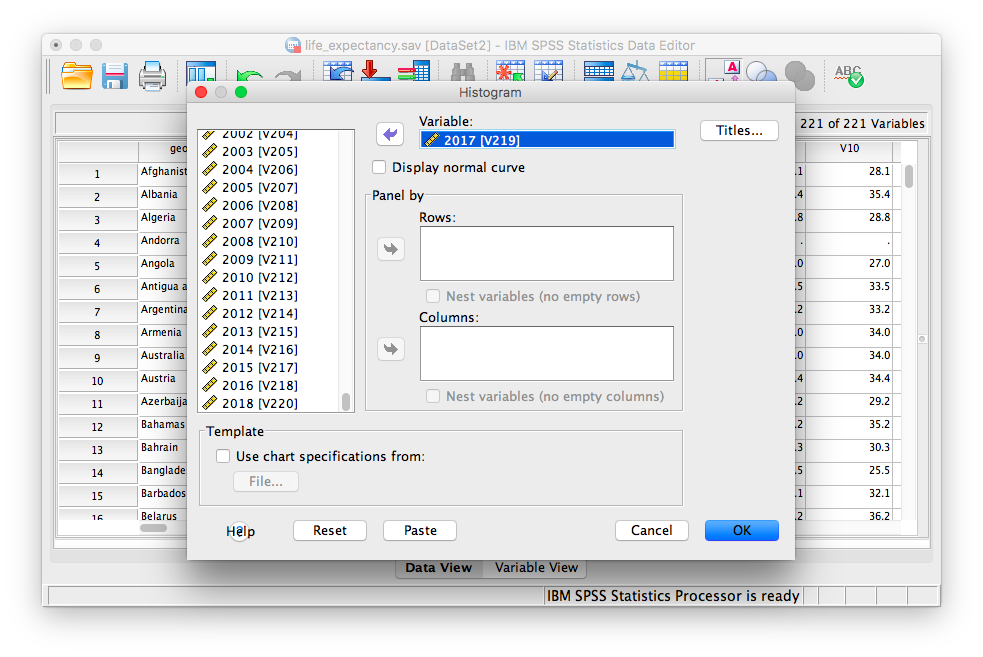
SPSS will produce an output window containing the distribution of life expectancy for the year 2017.
1.4.3.3 Scatterplots
Now, we will look to a different type of data plot; the scatterplot. A scatterplot allows us to visualize bivariate data, that is, data for which there are two measurements per individual. For example, we may ask whether life expectancy in a country (or how long you live, on average) is related to the average income. Using the life_expectancy.sav data file, let’s plot both variables: 2017 [v219] and income. The income variable in the spreadsheet refers to data collected in 2017 by the Better Life Initiative. Notice not all the countries listed have estimates for average annual income. For those that do, this value represents household net adjusted income (annual) in US dollars.
To create the scatterplot, let’s go to Graphs in the menu toolbar, then Legacy Dialogs, then Scatter.
You will choose Simple scatter, then click Define.
Next, indicate which variables (there are 2 this time!) you would like in the x- and y-axes. Use the arrows to place income in the x-axis field, and 2017 (V219) in the y-axis field. (For the purposes of graphing a scatterplot, it does not matter which variable goes into the y-axis and x-axis fields for now; you can reverse them if you’d like and you can still interpret the data similarly)
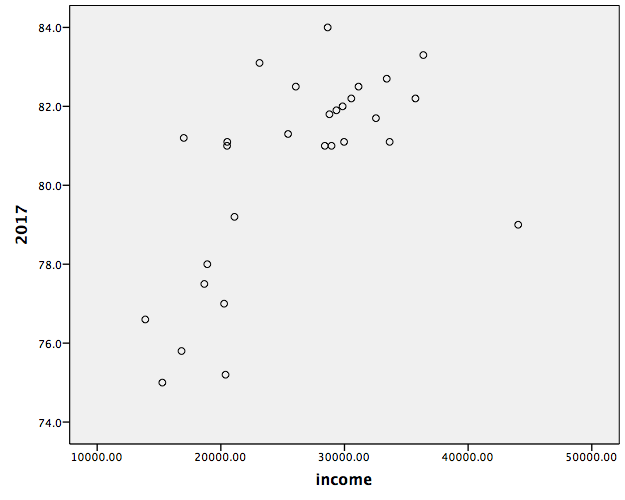
Then click OK. SPSS will produce output containing a scatterplot. What relationship do you notice? What happens to life expectancy the more individuals earn, on average?
1.4.4 Practice Problems
Create a histogram for life expectancy in the year 1800. Describe the distribution. How does it differ from the one we plotted for 2017?
Plot the life expectancy of each country in 1800 vs. that of 2018. What does this graph show you? What are your conclusions regarding the development of nations?