9 Chi Square
“10/8/2020 | Last Compiled: 2022-04-26”
9.1 Reading
Vokey & Allen29, Chapter 13.
9.2 Overview
This lab provides a conceptual foundation for understanding the chi square test using R.
9.3 Background
9.3.1 A brief history
Karl Pearson described the chi-square test in 1900.30 Also see Plackett, R. L.31 for additional context about the development of this test. Relatedly, Pearson had an undeniably large impact on the discipline of statistics; although a socio-historical account is beyond the scope of this lab, it is worth pointing out that Pearson (like many of his contemporaries) was heavily involved in the eugenics movement,32 and he not only developed statistical techniques, but also applied them to those causes (interested readers could see examples in Pearson’s publications in eugenics journals).
9.3.2 Chi-square distributions have fundamental properties that make them widespread in statistics
The chi-square (\(\chi^2\)) test, statistic, and associated distribution are fundamental to many other aspects of statistics. A full accounting of the many connections and mathematical relationships is beyond the scope of this lab (but see wikipedia articles on the chi-square test, and chi-square distribution ).
9.3.3 Debate about correct usage
The chi-square test has multiple uses in psychology, including tests of independence and goodness of fit. The “correct” usage of chi-square tests is not without debate. For example, roughly 50 years after Pearson, Lewis, D., & Burke, C. J.33 wrote a lengthy paper describing “uses and misuses” of chi-square tests in psychology. There were several replies by other authors who were identified as “misusing” the chi-square test. More recently, the suggestions of Lewis & Burke34 were revisited by Delucchi, K. L.35 These papers scratch the surface of the many uses and misuses of chi-square tests in psychology. An ongoing goal in our labs is to develop your conceptual understanding of the statistics you use so that you can justify why your usage is appropriate to your analysis.
9.3.4 Connection to previous lab concepts
In previous labs we have conducted statistical inference by adopting similar general procedures. We obtain sample data. We consider how the sample could have arisen by random sampling, and construct a sampling distribution. Then we compare our sample data to the sampling distribution to see if it was likely or unlikely to have been produced by chance. Sometimes we have simulated the sampling distribution, and other times we have used formulas to compute precise probabilities.
The chi-square test is another specific example of the general procedure described above. We can obtain sample data, compute a \(\chi^2\) statistic for the sample data, and then compare that statistic to a reference null distribution to determine the probability of obtaining that value by chance.
9.4 Practical I: chisq.test() in R
Base R comes with several functions for chi-square tests, including chisq.test() and the family of \(\chi^2\) distribution functions: dchisqu(), pchisqu(), qchisqu(), and rchisqu().
9.4.1 chisq.test()
The chisq.test() function performs basic tests of independence for vectors and contingency tables.
?chisq.test9.4.1.1 Test for a frequency vector
Inputting a single vector of values conducts a chi-square test with N-1 degrees of freedom. The test assumes equal probability of outcome by default, and reports the chi-square sample statistic, as a well as the p-value associated with a \(\chi^2\) distribution with N-1 degrees of freedom.
Toss a coin 50 times and receive 20 heads and 30 tails. Conduct a chi-square test of independence, and assume the theoretically expected frequencies are 25 and 25.
my_vals <- c(20,30)
(xsq <- chisq.test(my_vals))
#>
#> Chi-squared test for given probabilities
#>
#> data: my_vals
#> X-squared = 2, df = 1, p-value = 0.1573
xsq$statistic
#> X-squared
#> 2
xsq$observed
#> [1] 20 30
xsq$expected
#> [1] 25 25
xsq$residuals
#> [1] -1 1
sum(((xsq$observed - xsq$expected)^2) / xsq$expected)
#> [1] 2It is possible to specify different theoretical probabilities:
my_vals <- c(20,30)
chisq.test(my_vals, p = c(.25,.75))
#>
#> Chi-squared test for given probabilities
#>
#> data: my_vals
#> X-squared = 6, df = 1, p-value = 0.01431The vector can be any length, e.g., roll a dice 120 times and count the number of times each number from 1 to 6 occurs, then conduct a chi-square test of independence:
my_vals <- c(20,30,10,10,30,30)
chisq.test(my_vals)
#>
#> Chi-squared test for given probabilities
#>
#> data: my_vals
#> X-squared = 22.308, df = 5, p-value = 0.00045769.4.2 Independence test for a contingency table
A matrix describing a contingency table with positive values in rows and columns can also be inputted directly to the function. Here, the null hypothesis is that the “joint distribution of the cell counts in the contingency table is the product of row and column marginals”. The degrees of freedom is defined as \((r-1)(c-1)\), where \(r\) is the number of rows and \(c\) is the number of columns.
The following example is from the help file:
M <- as.table(rbind(c(762, 327, 468), c(484, 239, 477)))
dimnames(M) <- list(gender = c("F", "M"),
party = c("Democrat","Independent", "Republican"))
(Xsq <- chisq.test(M)) # Prints test summary
#>
#> Pearson's Chi-squared test
#>
#> data: M
#> X-squared = 30.07, df = 2, p-value = 2.954e-07
Xsq$observed # observed counts (same as M)
#> party
#> gender Democrat Independent Republican
#> F 762 327 468
#> M 484 239 477
Xsq$expected # expected counts under the null
#> party
#> gender Democrat Independent Republican
#> F 703.6714 319.6453 533.6834
#> M 542.3286 246.3547 411.3166
Xsq$residuals # Pearson residuals
#> party
#> gender Democrat Independent Republican
#> F 2.1988558 0.4113702 -2.8432397
#> M -2.5046695 -0.4685829 3.2386734
Xsq$stdres # standardized residuals
#> party
#> gender Democrat Independent Republican
#> F 4.5020535 0.6994517 -5.3159455
#> M -4.5020535 -0.6994517 5.3159455
Xsq$p.value
#> [1] 2.953589e-07
Xsq$statistic
#> X-squared
#> 30.070159.5 Conceptual I: \(\chi^2\) distribution, sample statistic, and test
Chi-square (\(\chi^2\)) statistics can be confusing because \(\chi^2\) can refer to distributions, a sample statistic, and statistical inference tests.
The \(\chi^2\) distribution is a family of distributions that arise when you sum the squared values of random samples from a unit normal distribution:
\(\chi^2 = \sum_{i=1}^k Z_i^2\)
Where, \(Z_i^2\) is a random deviate from a unit normal distribution (mean = 0, sd =1), and \(k\) is the number of random samples (also known as the degrees of freedom, or number of samples free to independently vary). When \(k=1\), the \(\chi^2\) distribution is a unit normal distribution squared.
The \(\chi^2\) sample statistic is a formula that can be applied to frequency data to summarize the amount by which the observed frequencies differ from theoretically expected frequencies.
\(\chi^2 = \sum{\frac{(\text{Observed} - \text{Expected})^2}{\text{Expected}}}\)
\(\chi^2 = \sum_{i=1}^n{\frac{(\text{O}_i - \text{E}_i)^2}{\text{E}_i}}\)
\(\chi^2\) statistical tests (such as a test of independence, or goodness of fit) are used for inference about the role of chance in producing observed frequency data. The process involves computing the \(\chi^2\) sample statistic on observed frequency data, then comparing the obtained value to a \(\chi^2\) distribution with the same degrees of freedom as the sample. The probability of obtaining the \(\chi^2\) sample statistic or larger generally approximates the probability that an independent random sampling process could have produced deviations from the expected frequencies as large as or larger than that found in the sample.
9.5.1 The \(\chi^2\) sample statistic
Below are two ways of writing the formula for the \(\chi^2\) sample statistic.
\(\chi^2 = \sum{\frac{(\text{Observed} - \text{Expected})^2}{\text{Expected}}}\)
\(\chi^2 = \sum_{i=1}^n{\frac{(\text{O}_i - \text{E}_i)^2}{\text{E}_i}}\)
The \(\chi^2\) sample statistic is used to summarize obtained frequency data, specifically in a way that relates the obtained frequencies to theoretically expected frequencies.
For example, if you tossed a coin 50 times, and found the following observed frequencies of heads and tails, you could compare them to the expected frequencies if the coin was fair.
coin_toss <- data.frame(outcome = c("H","T"),
O = c(23,27),
E = c(25,25))
knitr::kable(coin_toss)| outcome | O | E |
|---|---|---|
| H | 23 | 25 |
| T | 27 | 25 |
Thus, each outcome has an observed value (\(O_i\)) and expected value (\(E_i\)), and \(\chi^2\) can be computed:
library(dplyr)
coin_toss <- coin_toss %>%
mutate(d = O - E) %>%
mutate(d_sq = d^2) %>%
mutate(div = d_sq/E )
knitr::kable(coin_toss)| outcome | O | E | d | d_sq | div |
|---|---|---|---|---|---|
| H | 23 | 25 | -2 | 4 | 0.16 |
| T | 27 | 25 | 2 | 4 | 0.16 |
# compute chi-square
sum(coin_toss$div)
#> [1] 0.32
# compute chi-square
O <- c(23,27)
E <- c(25,25)
sum(((O-E)^2)/E)
#> [1] 0.32
# compute chi-square
chisq.test(x=c(23,27))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(23, 27)
#> X-squared = 0.32, df = 1, p-value = 0.5716The above shows two ways to compute \(\chi^2\) for this example, including using the base R function \(chisq.test()\). The obtained value of .32 in our case is fairly small because the differences between the obtained and expected frequencies were fairly small. If the differences were larger, then the \(\chi^2\) sample statistic would be much larger, e.g:
chisq.test(x=c(47,3))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(47, 3)
#> X-squared = 38.72, df = 1, p-value = 4.892e-10Both times the base R function returned the \(\chi^2\) sample statistic (computed from the data and assumed theoretical frequencies). The function also return information about degrees of freedom (df), and a p-value. These additional values refer to information from a \(\chi^2\) distribution. Under appropriate conditions, the \(\chi^2\) sample statistic can be compared to a \(\chi^2\) distribution for the purposes of statistical inference.
9.5.2 The \(\chi^2\) distribution
The shape of \(\chi^2\) distribution depends on a parameter called \(k\). When, \(k = 1\), the \(\chi^2\) distribution is defined as the unit normal distribution squared.
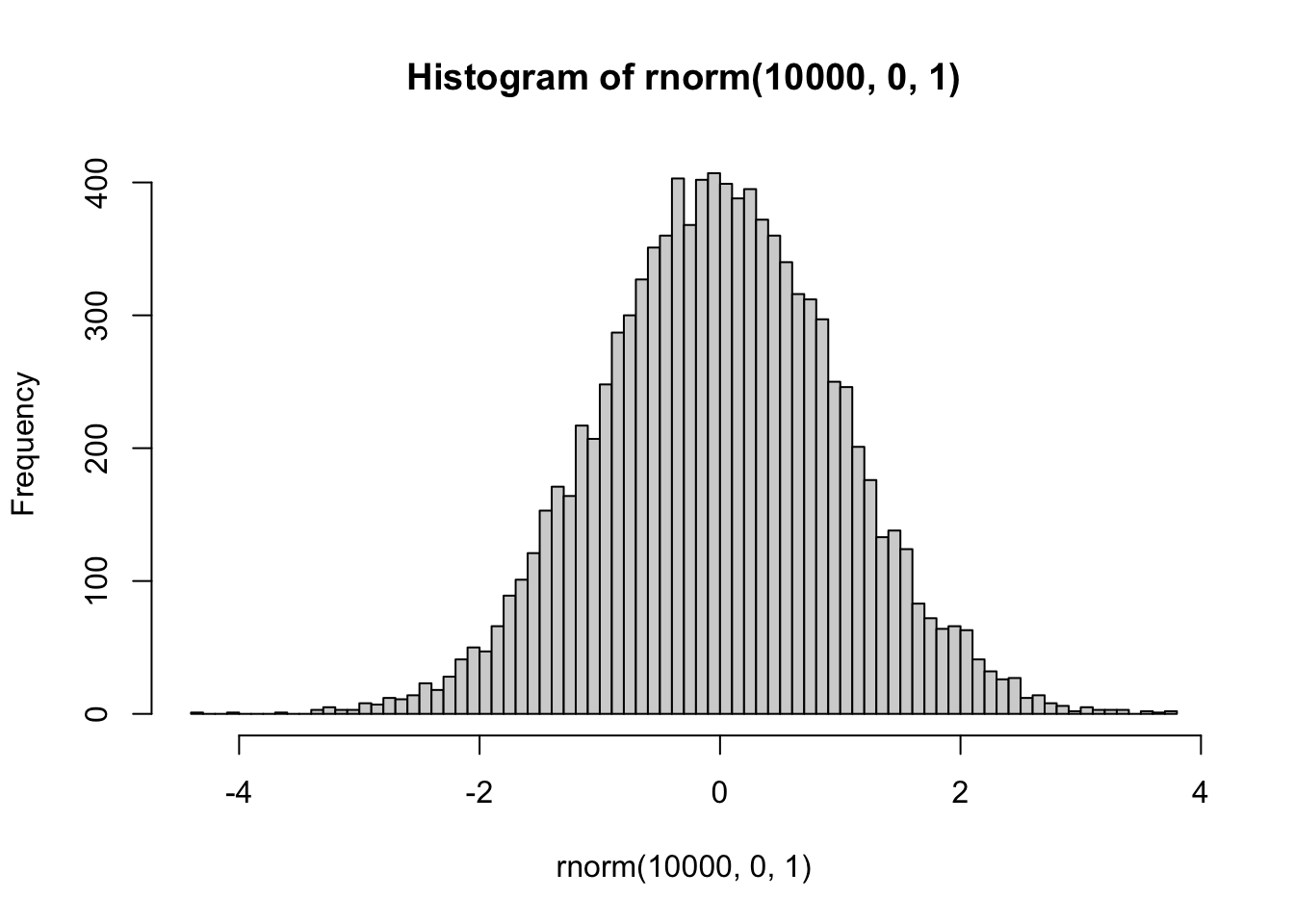
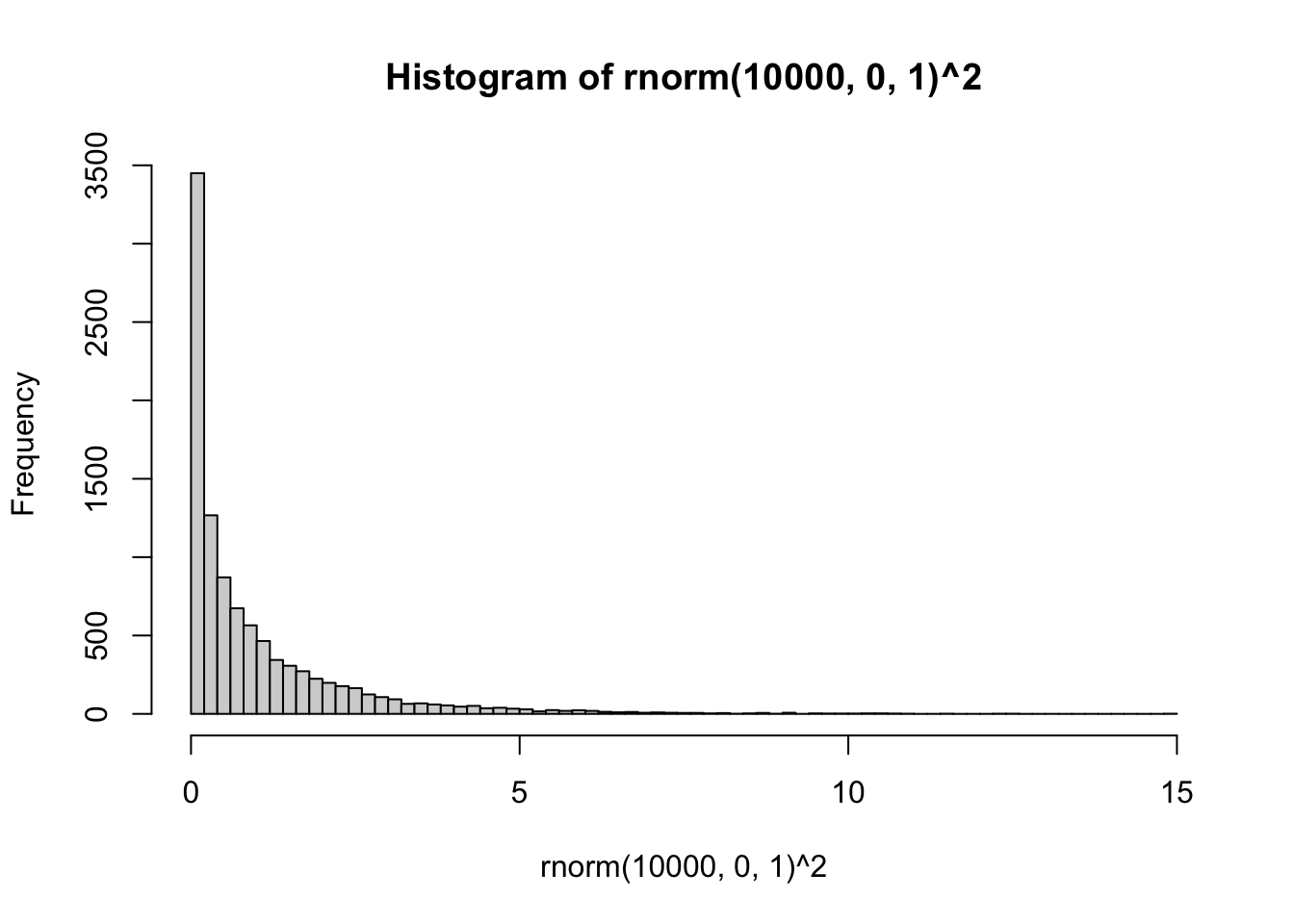
R has distribution functions for \(\chi^2\), including dchisq(), pchisq(), qchisq(), rchisq(). So, if we sampled random deviates using rchisq(), with k = 1 (equivalent to df = 1), we should get the same histogram as above:
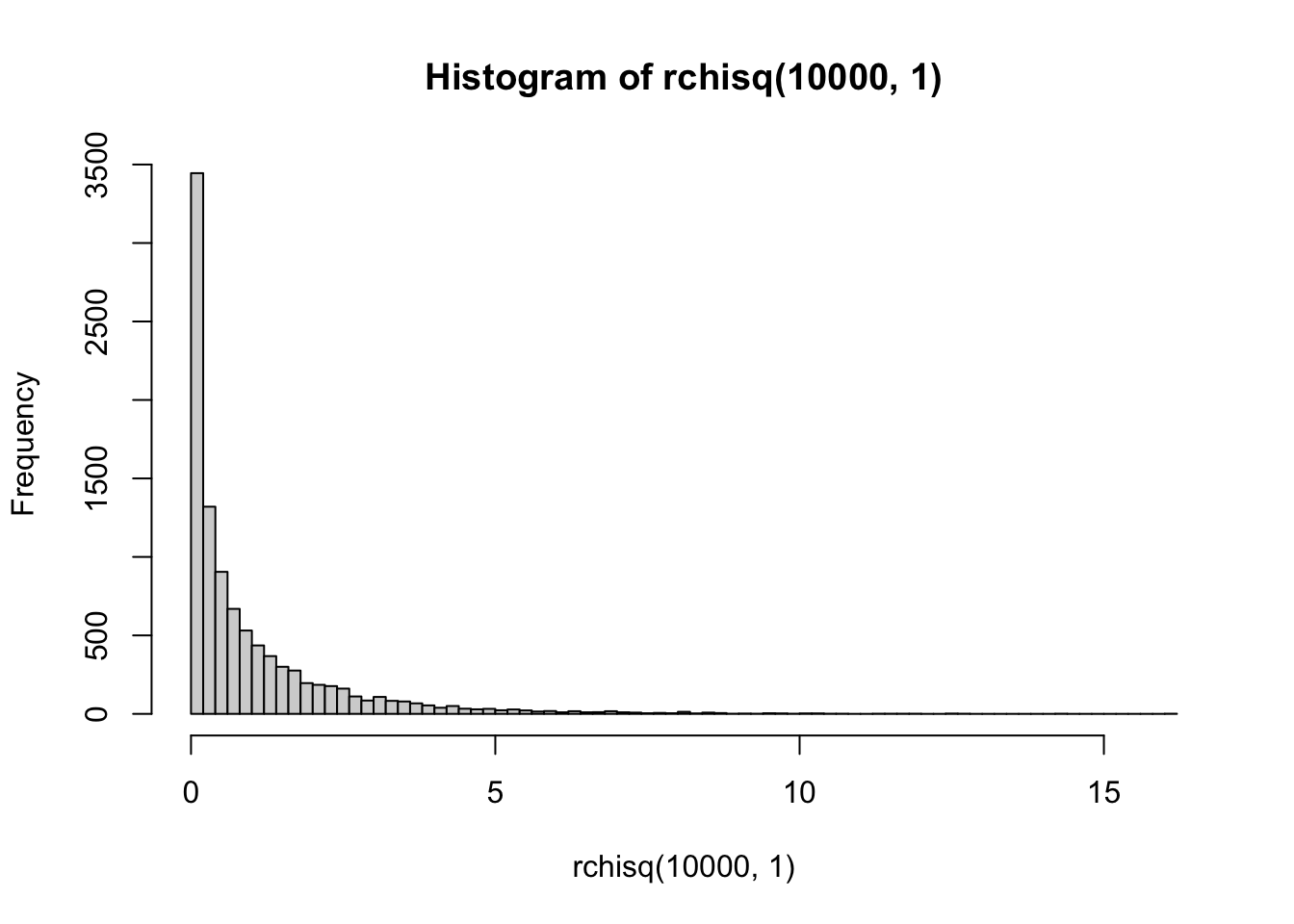
So, at its simplest, \(\chi^2\) is just the normal distribution squared.
When \(k > 1\), the \(\chi^2\) distribution is defined as:
\(\chi^2 = \sum_{i=1}^k Z_i^2\)
Where, \(Z_i\) are independent samples from a unit normal distribution. In other words, \(\chi^2\) is the distribution of the sum of squared values from a unit normal distribution, and \(k\) is the number of independent samples in each squared sum.
To clarify, let’s use R:
# k = 1
from_normal <- replicate(10000, rnorm(1,0,1)^2)
from_chisq <- rchisq(10000,1)
plot_df <- data.frame(values = c(from_normal,
from_chisq),
source = c("normal^2","chisq"))
library(ggplot2)
ggplot(plot_df, aes(x=values))+
geom_histogram(bins=100)+
ggtitle("k=1")+
facet_wrap(~source)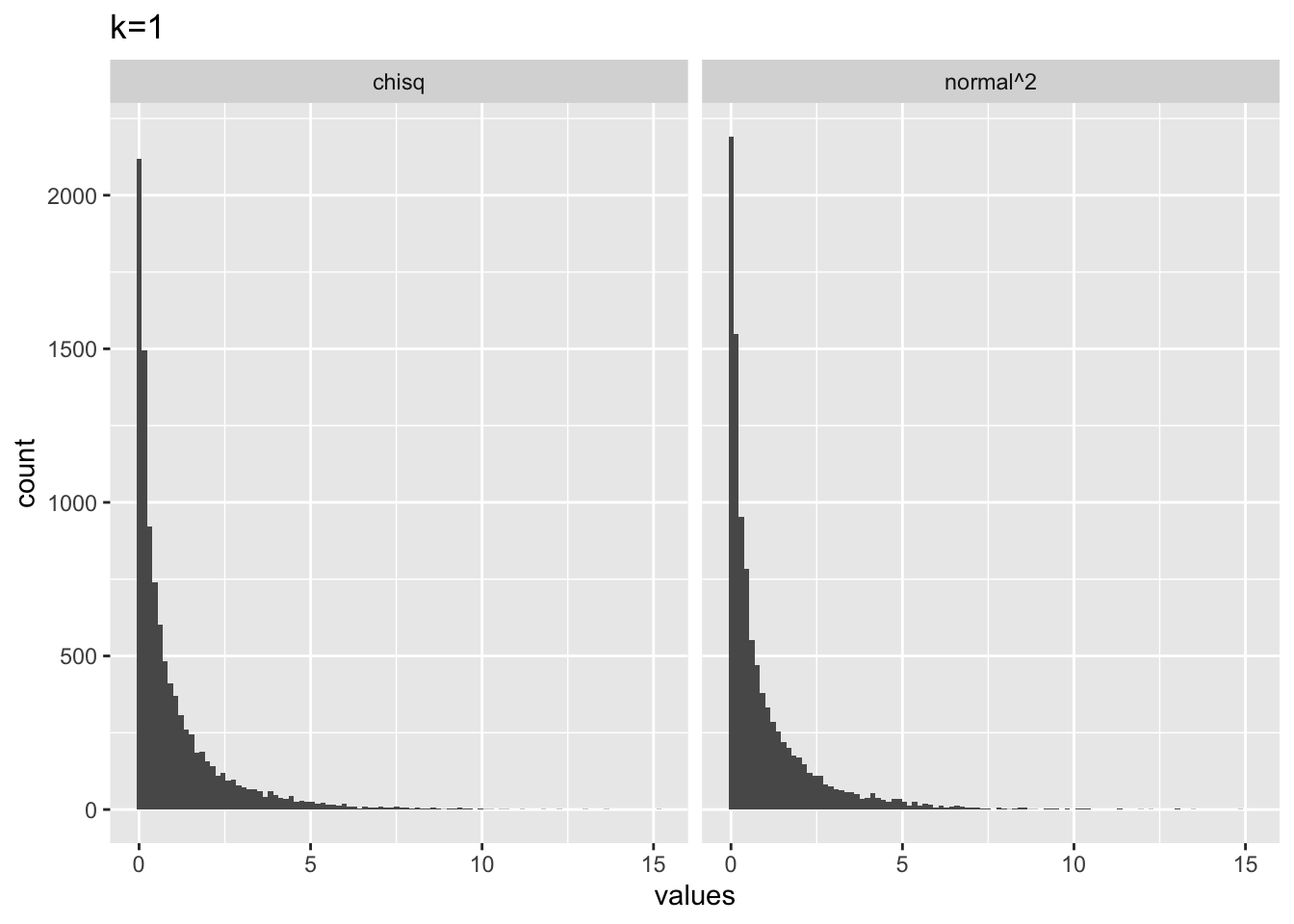
# k = 2
from_normal <- replicate(10000, sum(rnorm(2,0,1)^2))
from_chisq <- rchisq(10000,2)
plot_df <- data.frame(values = c(from_normal,
from_chisq),
source = c("normal^2","chisq"))
library(ggplot2)
ggplot(plot_df, aes(x=values))+
geom_histogram(bins=100)+
ggtitle("k=2")+
facet_wrap(~source)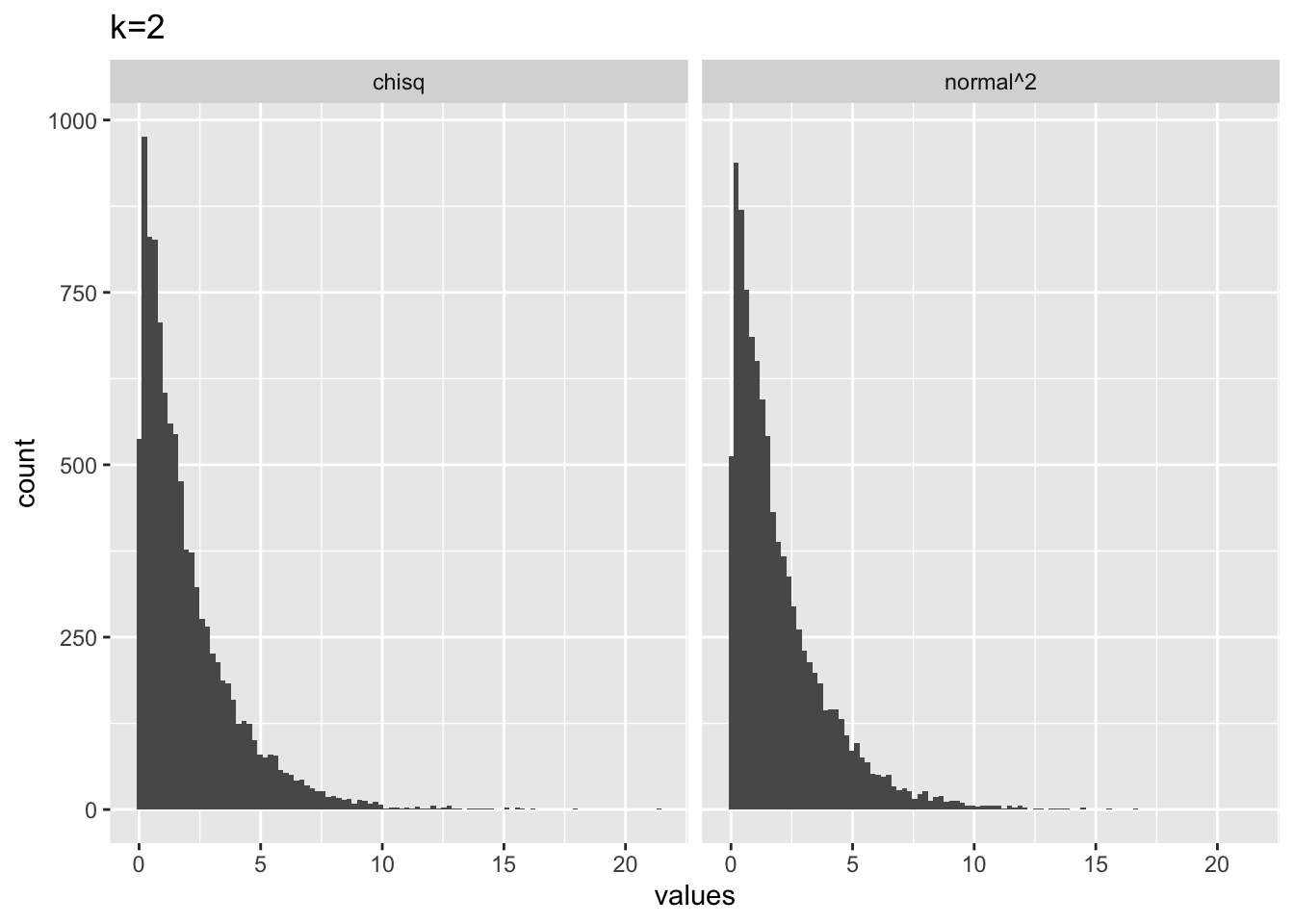
# k = 3
from_normal <- replicate(10000, sum(rnorm(3,0,1)^2))
from_chisq <- rchisq(10000,3)
plot_df <- data.frame(values = c(from_normal,
from_chisq),
source = c("normal^2","chisq"))
library(ggplot2)
ggplot(plot_df, aes(x=values))+
geom_histogram(bins=100)+
ggtitle("k=3")+
facet_wrap(~source)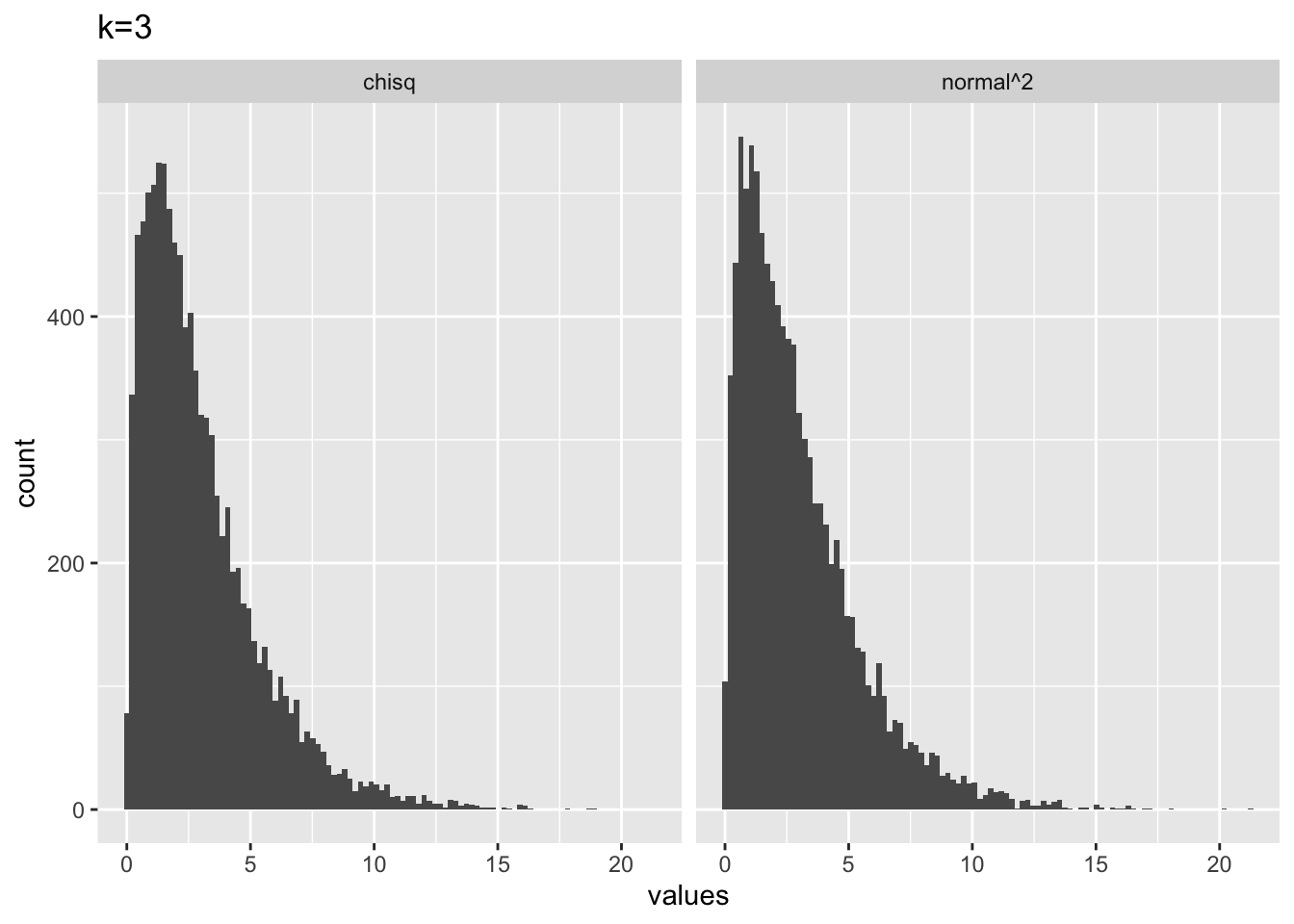
# k = 5
from_normal <- replicate(10000, sum(rnorm(5,0,1)^2))
from_chisq <- rchisq(10000,5)
plot_df <- data.frame(values = c(from_normal,
from_chisq),
source = c("normal^2","chisq"))
library(ggplot2)
ggplot(plot_df, aes(x=values))+
geom_histogram(bins=100)+
ggtitle("k=5")+
facet_wrap(~source)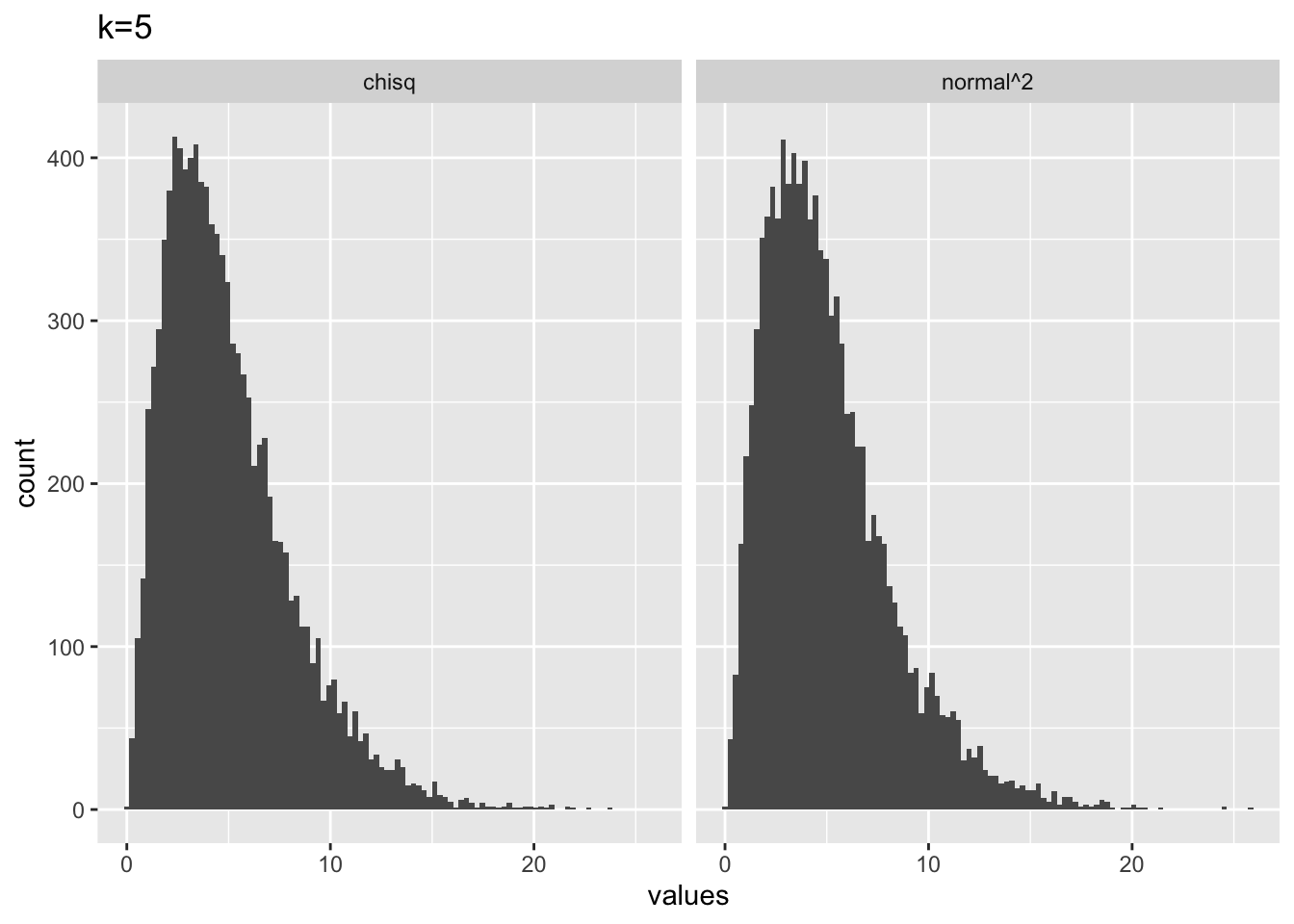
We can get a glimpse of what the \(\chi^2\) distribution looks like across a range of \(k\) by plotting the pdf (probability density function), using dchisq().
plot_df <- data.frame(values = c(dchisq(x=seq(0,20,length.out = 100), df=1),
dchisq(x=seq(0,20,length.out = 100), df=3),
dchisq(x=seq(0,20,length.out = 100), df=5),
dchisq(x=seq(0,20,length.out = 100), df=9),
dchisq(x=seq(0,20,length.out = 100), df=11)
),
x = rep(seq(0,20,length.out = 100),5),
k = as.factor(rep(c(1,3,5,9,11), each = 100))
)
ggplot(plot_df, aes(x = x, y=values, color=k, group=k))+
geom_line()+
ylab("density")+
xlab("chi-squared")+
scale_x_continuous(breaks=0:20)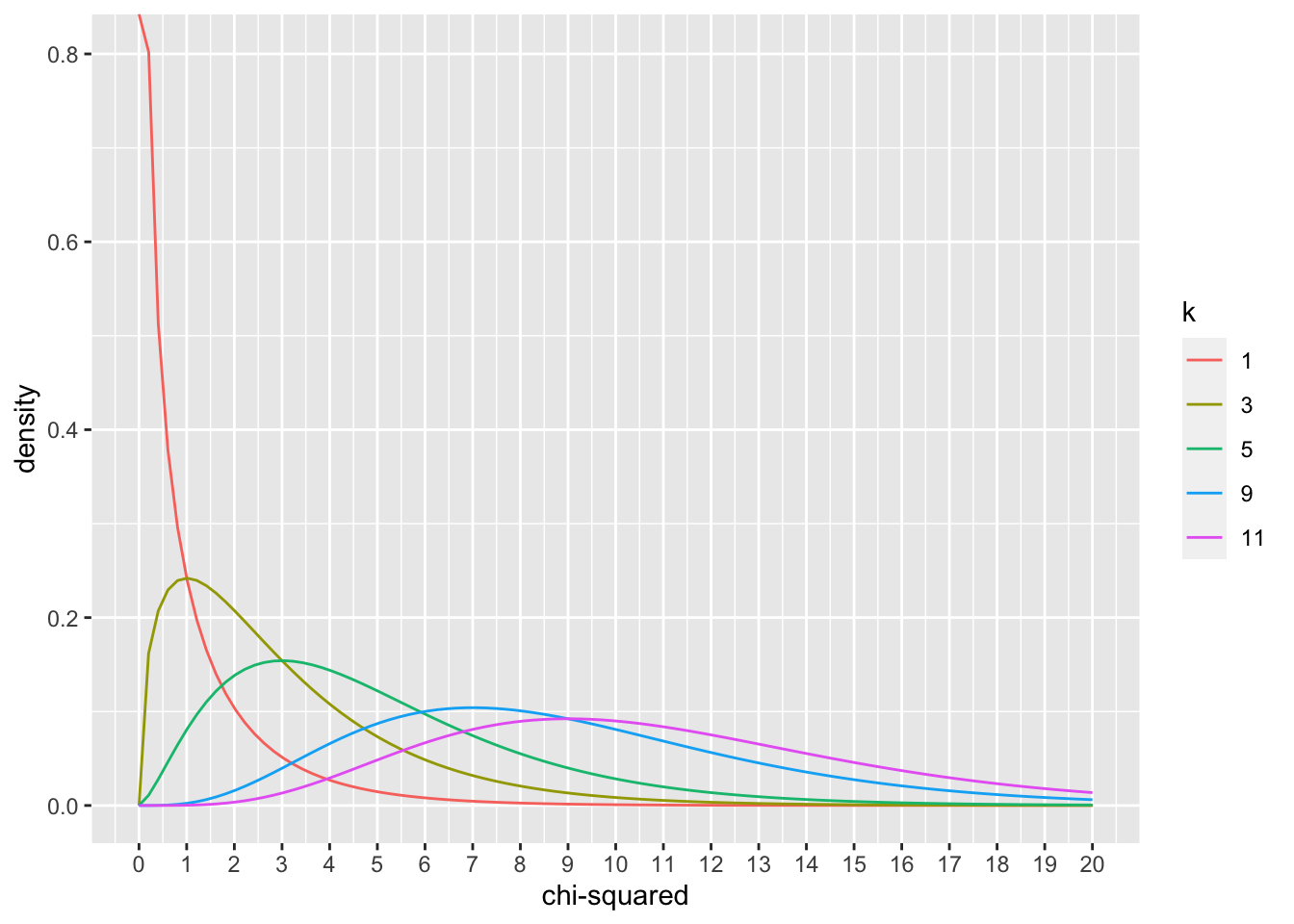 ### Developing intuitions about \(\chi^2\)
### Developing intuitions about \(\chi^2\)
- Let’s say you randomly sampled 5 numbers from a unit normal distribution (mean = 0 and sd =1), and then you squared those numbers, and then added them all up. What would you expect this number to be?
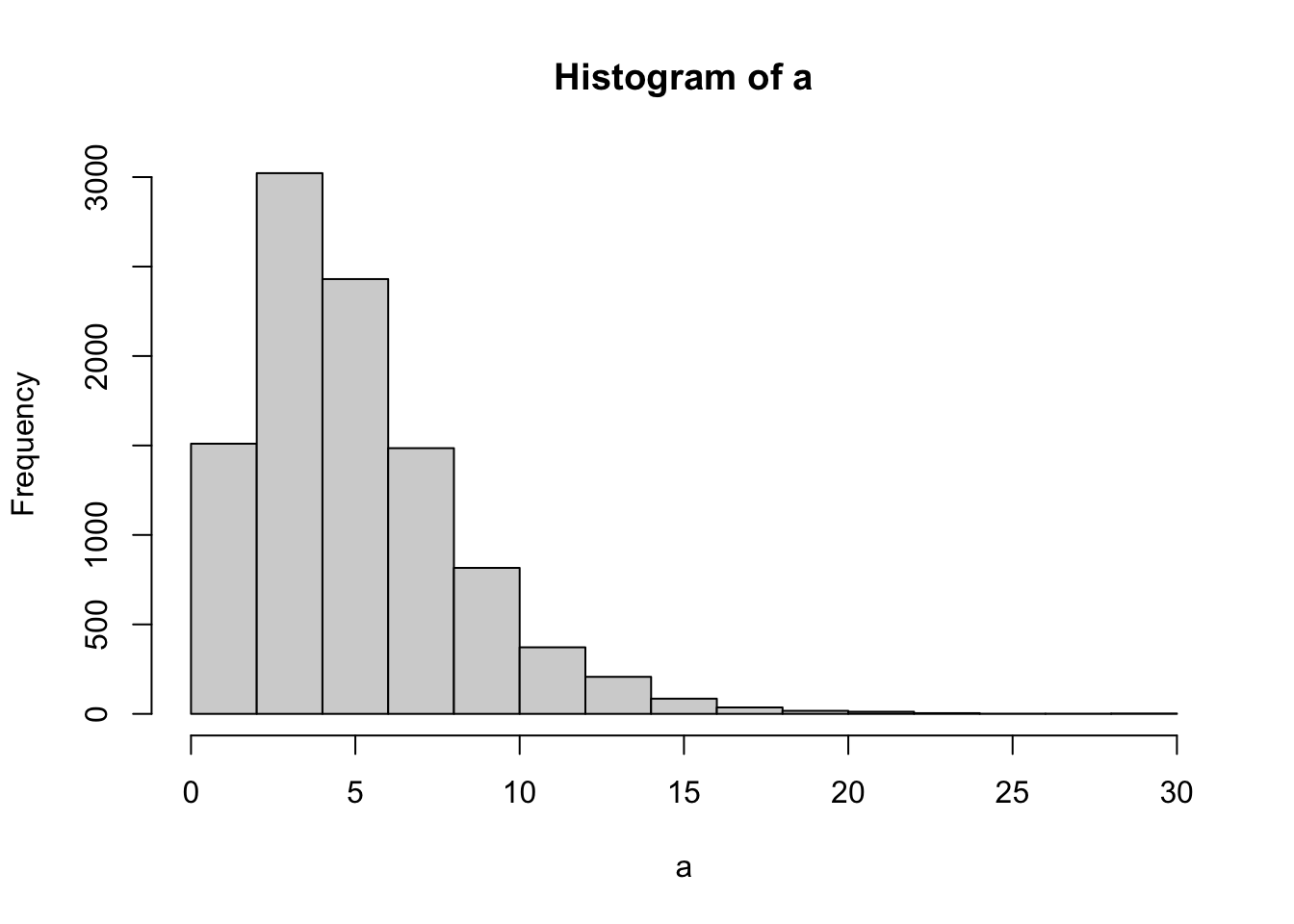
The answer is that this number will be distributed as a \(\chi^2\) with \(k=5\), referring to the situation of summing the squares of 5 samples from a unit normal distribution.
- Why does the \(\chi^2\) distribution change shape as \(k\) increases? If \(k\) was a big number like 60, what kind of shape could I expect? If I know \(k\), what should I expect the mean of the \(\chi^2\) distribution to be? Answering these questions requires building intuition about \(\chi^2\).
In the following, I will take random samples from a unit normal distribution:
What is the expected mean of a unit normal distribution?
If we square all of the values that we sample from a unit normal distribution (equivalent to \(\chi^2\) with \(k=1\)), then what would the mean of those squared values be?
It turns out the answer is 1. There will be no negative values because we are squaring everything. About 68% of the values in a unit normal are between -1 and 1, so squaring all of those will make values between 0 and 1, the rest of the values get increasingly bigger than 1. They all balance out at 1, which is the mean of a squared normal distribution. In other words, the mean of a \(\chi^2\) is the same as the \(k\) parameter, also called degrees of freedom.
For example, the mean of 10,000 numbers drawn from a \(\chi^2\) with k = 10, is:
Another way to think about this is to recognize that the expected value (mean) from a squared unit normal distribution is 1. So, if you take 10 values from that distribution (i.e., when k = 10), then you are planning to sum up the 10 values that you get, and the expected value for each is 1…summing up 10 ones, gives you 10. The same expectations can be applied to \(\chi^2\) distributions of any \(k\).
9.6 Conceptual II: Examining the approximation
In lecture we discussed that the binomial distribution converges on the normal distribution in the long run. This is one of the properties that allows the \(\chi^2\) distribution to approximate properties of the binomial distribution.
First, we can visually see that a binomial distribution becomes normally distributed in the long run by simulation. Each simulation involves 10,000 sets of coin flips. The first histogram involves a set of 10 coin flips, and displays the frequency of each possible outcome (# of heads)s. The second histogram shows sets of 100 coin flips. Here, the range of possible outcomes increases, and they appear to be distributed more normally. As the number of flips in the set increases, the distribution of possible outcomes approaches a normal distribution.
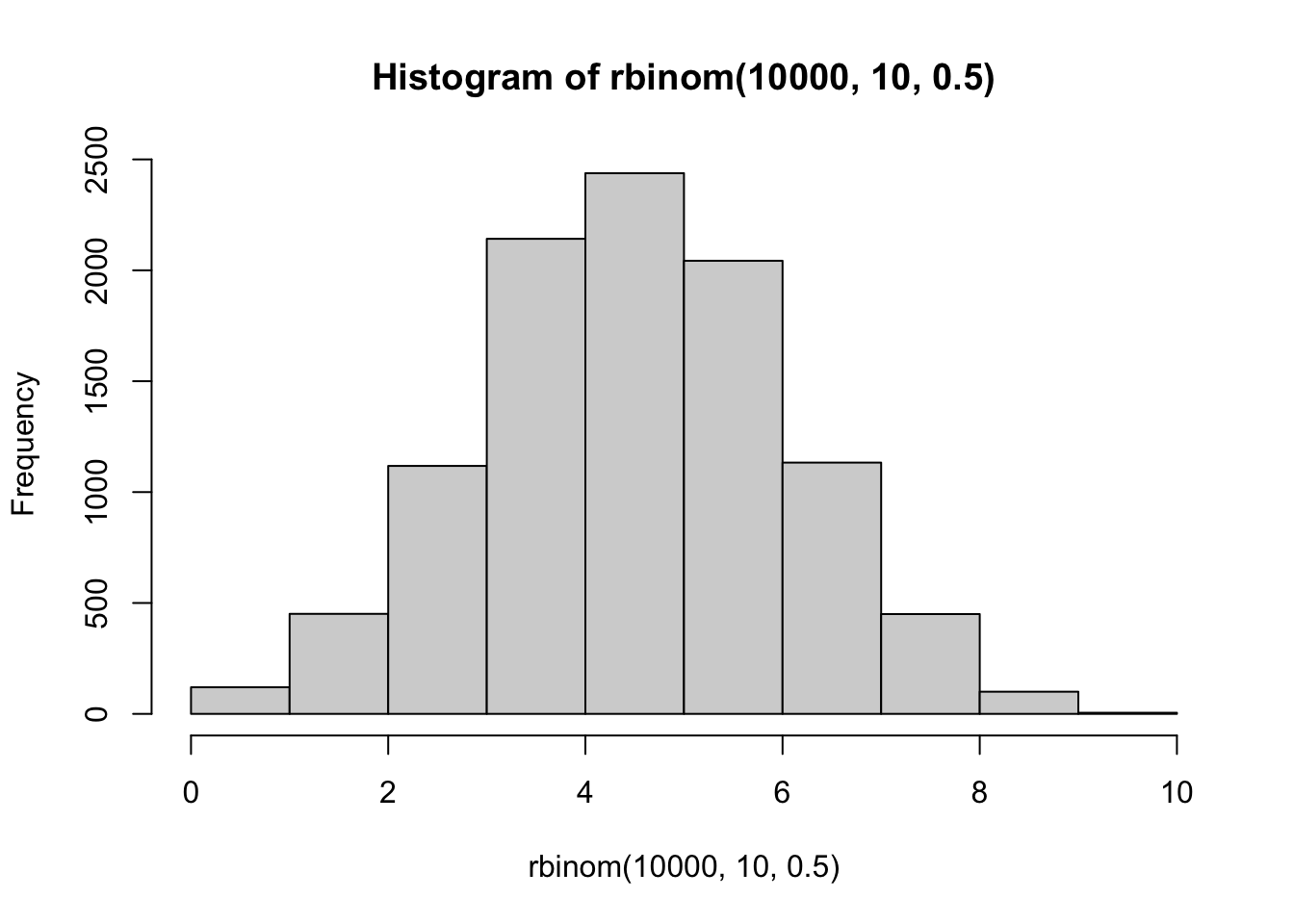
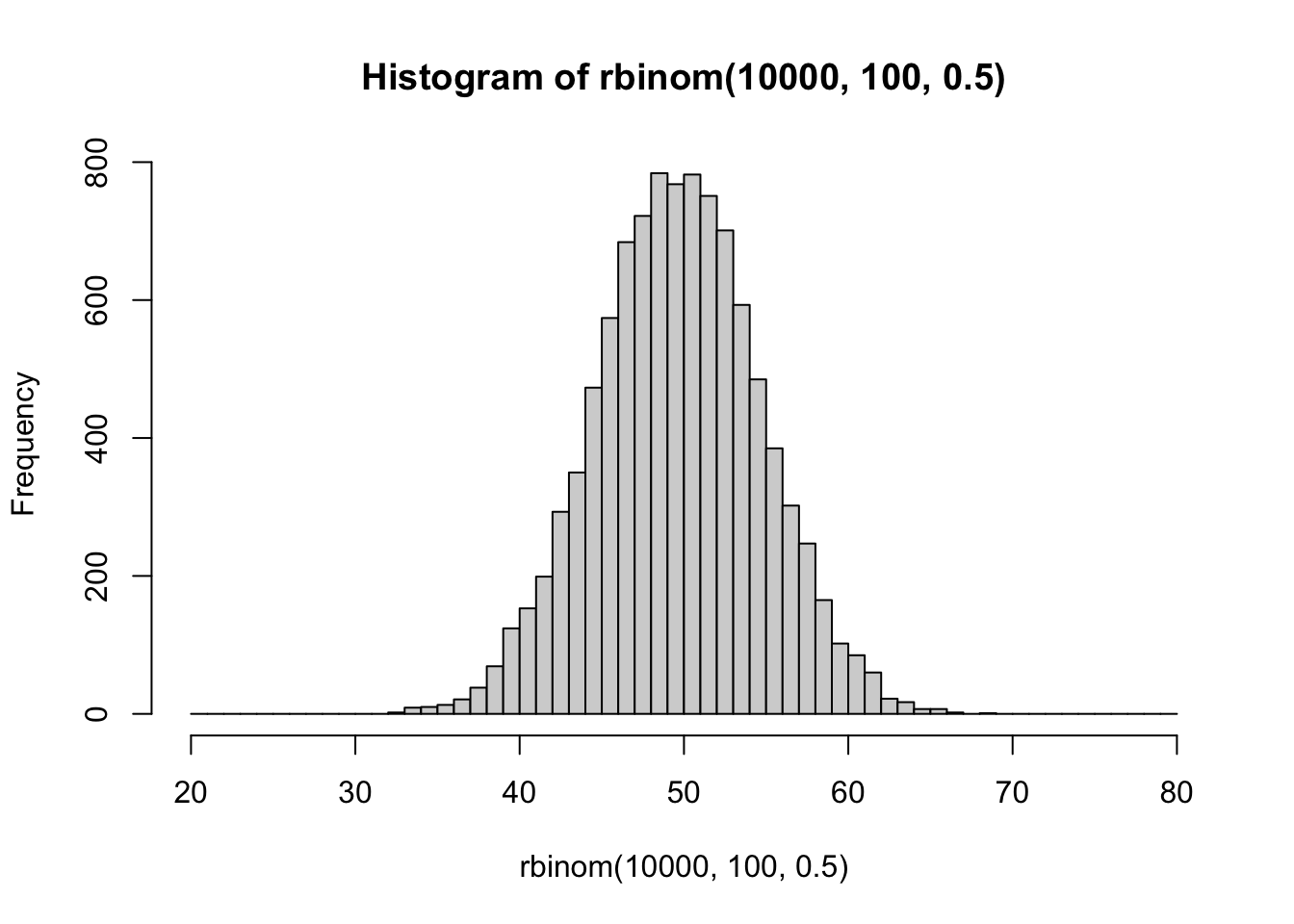 Second, let’s develop a sense of the idea that the \(\chi^2\) test is approximation of the binomial test.
Second, let’s develop a sense of the idea that the \(\chi^2\) test is approximation of the binomial test.
Consider another coin flipping scenario. Let’s say a coin is flipped 10 times, and there are 2 heads. What is the p-value for a two-tailed test, specifically the probabiltiy of getting 2 or less heads, or 8 or more heads.?
We could use the binomial test, and compute the exact probability.
pbinom(2,10,.5, lower.tail = TRUE)*2
#> [1] 0.109375We could also use a \(\chi^2\) test as an approximation:
chisq.test(c(2,8))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(2, 8)
#> X-squared = 3.6, df = 1, p-value = 0.05778In this case there wouldn’t be a good reason to use the \(\chi^2\) test, because the binomial test provides an exact probability. Also, because the expected frequencies are very small here, the p-value \(\chi^2\) test is about half as small as it should be.
However, if we consider sets of coin flips that are much larger than 10, we increase the expected frequencies (which allows closer convergence to a normal distribution), and the \(\chi^2\) and binomial tests both return p-values that are increasingly similar.
pbinom(40,100,.5, lower.tail = TRUE)*2
#> [1] 0.05688793
chisq.test(c(40,60))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(40, 60)
#> X-squared = 4, df = 1, p-value = 0.0455
pbinom(450,1000,.5, lower.tail = TRUE)*2
#> [1] 0.001730536
chisq.test(c(450,550))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(450, 550)
#> X-squared = 10, df = 1, p-value = 0.001565
pbinom(4900,10000,.5, lower.tail = TRUE)*2
#> [1] 0.04658553
chisq.test(c(4900,5100))
#>
#> Chi-squared test for given probabilities
#>
#> data: c(4900, 5100)
#> X-squared = 4, df = 1, p-value = 0.04559.7 Lab 9 Generalization Assignment
9.7.1 Instructions
In general, labs will present a discussion of problems and issues with example code like above, and then students will be tasked with completing generalization assignments, showing that they can work with the concepts and tools independently.
Your assignment instructions are the following:
- Work inside the R project “StatsLab1” you have been using
- Create a new R Markdown document called “Lab9.Rmd”
- Use Lab9.Rmd to show your work attempting to solve the following generalization problems. Commit your work regularly so that it appears on your Github repository.
- For each problem, make a note about how much of the problem you believe you can solve independently without help. For example, if you needed to watch the help video and are unable to solve the problem on your own without copying the answers, then your note would be 0. If you are confident you can complete the problem from scratch completely on your own, your note would be 100. It is OK to have all 0s or 100s anything in between.
- Submit your github repository link for Lab 9 on blackboard.
9.7.2 Problems
- The following paper links to open data, and describes a design where two chi-square tests are performed for Experiment 1 (A copy of this paper will be made available).
Silver, A. M., Stahl, A. E., Loiotile, R., Smith-Flores, A. S., & Feigenson, L. (2020). When Not Choosing Leads to Not Liking: Choice-Induced Preference in Infancy. Psychological Science, 0956797620954491.
Obtain the data from the online repository, show your code for loading it into R, then conduct the same tests reported in Experiment 1 that the authors conducted. These include one binomial test, and two chi-square tests. Briefly report your re-analysis, and discuss whether you obtained the same values as the authors did (6 points).
Important Note: In my own re-analysis I was able to obtain all of the same values that the authors provided in their results section. However, in my view the authors also misused the chi-square test, especially for the test of independence involving age. So, it is ok if you are unable to reproduce that analysis. However, it is instructive to try and reproduce what the authors did to form an opinion about whether the test was applied in a sound manner.
Solution script: I am also providing the .rmd for lab 9 that I wrote in the solution video here https://github.com/CrumpLab/psyc7709Lab/blob/master/lab_solutions/Lab9.Rmd.
Update on misuse of chi-square test in the above paper. As we discussed in class and in the solution video, it appears we accidentally found an example in the recent literature where a chi-square test was used incorrectly. In the solution video I didn’t provide a clear reason to demonstrate why the chi-square test was misused. So, I thought I would write an addendum to this lab.
To recap, the authors measured a choice made by 21 infants. The age of each infant was measured in months (to two decimal places). They reported a chi-square test of independence to determine whether age was independent of the choice. For example, they reported: \(\chi^2\) (19,N=21) =18.24,p=.506. These values are in some sense correct. For example:
pchisq(18.24, 19, lower.tail = FALSE)
#> [1] 0.5064639However, it appears that the authors treated the infant’s ages, measured a continuous variable, as a categorical variable. And, as it happened, there were two infants who happened to be exactly 11.66 months old. As a result, there were 21 infants, and 20 different age categories. If a contingency table is constructed to represent 20 age categories, and 2 choice options, you get a 20x2 table. This table has (20-1)(2-1) = 19 degrees of freedom. In my solution video I showed an example of how the authors might have constructed that table from their data, and I was able to obtain the same chi-square value that they reported, suggesting that they did construct such a table.
There are several problems here. One of the problems that I will focus on is the conversion of a continuous age variable into a categorical variable. I was expecting the authors to bin ages, say into two categories: younger vs. older. Instead, they used each infant’s age as a category level. It happened to be the case that two infants had exactly the same age (11.66 months), but if that hadn’t happened, the table would have had 21 levels for age (because there were 21 infants).
Consider what occurs if you treat each subject as a unique level in a contingency table, especially in an experiment that involves the subject making a single choice between two alternatives. We will see that the answer is, you always get the same chi-square value. No matter what the subjects do.
Here is an example contingency table with 5 subjects. In this case, each column represents a subject. Row 1 represents choice A, and row 2 choice 2. Each subject makes a choice, and their choice is counted in the appropriate row.
This is a contingency table, so it is possible to compute a chi-square test on this table.
chisq.test(replicate(5,sample(c(1,0),2)))
#>
#> Pearson's Chi-squared test
#>
#> data: replicate(5, sample(c(1, 0), 2))
#> X-squared = 5, df = 4, p-value = 0.2873However, look at what happens. We obtain a chi-squared value of 5. And, this is what will always happen, no matter what choices each subject makes:
Every time this function runs, the choices made by each simulated subject are randomized. However, no matter what happens, the chi-square value is always five.
chisq.test(replicate(5,sample(c(1,0),2)))
#>
#> Pearson's Chi-squared test
#>
#> data: replicate(5, sample(c(1, 0), 2))
#> X-squared = 5, df = 4, p-value = 0.2873This is effectively what the authors did. For example, consider what would happen to the authors data if they excluded the two infants who had the exact same age. That table would have choices from 19 infants.
We can simulate any possible outcome this way:
chisq.test(replicate(19,sample(c(1,0),2)))
#>
#> Pearson's Chi-squared test
#>
#> data: replicate(19, sample(c(1, 0), 2))
#> X-squared = 19, df = 18, p-value = 0.3918No matter choices the infants make (either A or B), they will always make one of them, and not the other. And, the observed chi-square value will always be the same as the number of subjects. So, this test does more to confirm the number of the infants used in the experiment than it does to assess the independence of age from the choices.
Finally, if you create a contingency table where each subject has their own category level…and then conduct a chi-square test of independence to see if the subjects are independent from the choices that they made, I would think the major problem there is that the subjects couldn’t be independent of the choices they made, because they were the ones making the choices.